Chap1笔记
Chapter 1: Computer Abstractions and Technology¶
-
RISC Architecture (Reduced Instruction Set Computer)
指令执行使用了尽可能少的时钟周期、指令编码长度定长等,提高了CPU和编译的效率
Computer Organization¶
-
Decomposability of computer systems
-
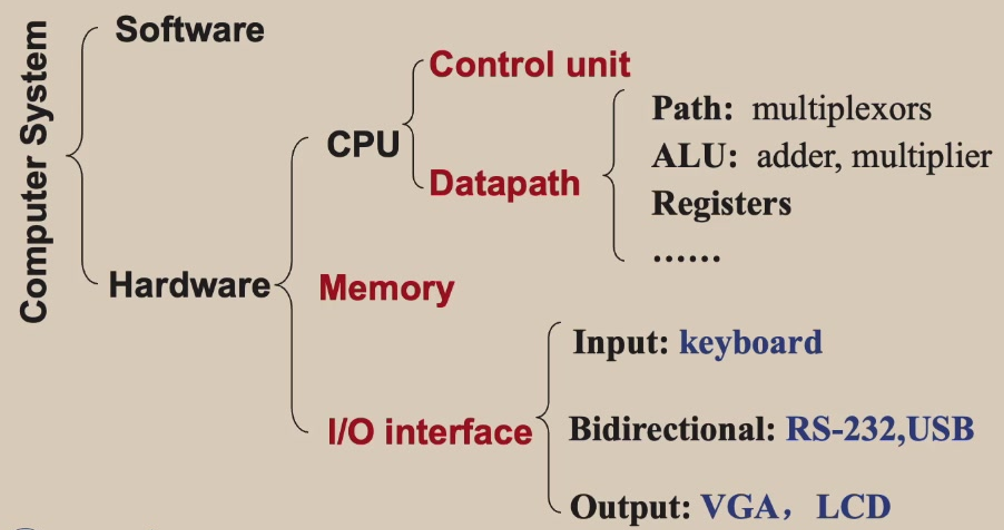
Five Classic Components of Hardware

-
CPU Processor
Active part of the computer, containing the datapath(进行数据运算操作) and control(根据程序的指示去控制datapath, memory, I/O devices) & adding numbers, testing numbers, signaling I/O devices to activate and so on.
-
Memory:
-
Memory: the storage area programs that are kept and that contains the data needed by the running programs
-
Main Memory: volatile; used to hold programs while they are running.
-
Second Memory: Nonvolatile; used to store programs and data between runs.
-
Volatile (易失性): DRAM, SRAM
-
Nonvolatile (非易失性): 固态硬盘/闪存, 硬盘
-
-
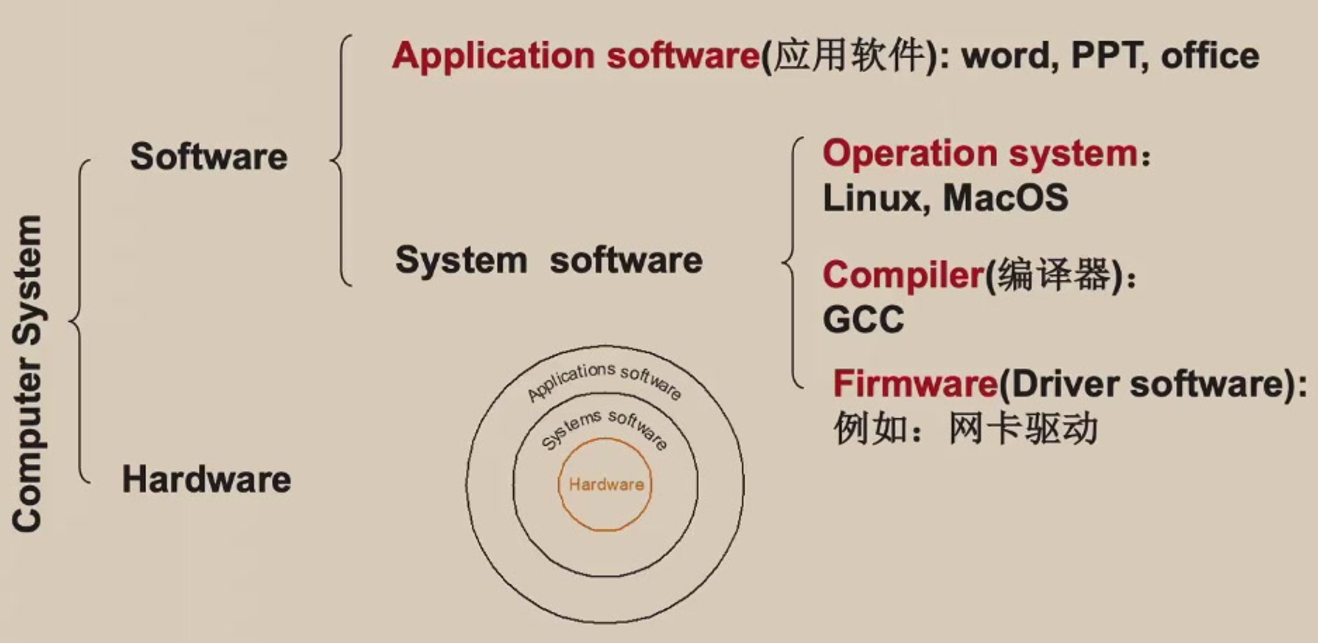
Software Categorization
-
Categorize software by its use: Systems software & Application software
-
Operating System:
-
Compiler: Translation of a program written in HLL
-
Firmware: software specially designed for a piece of hardware
-
-
From a High-Level Language to the Language of Hardware
-
Lower-level details are hidden to higher levels (低级语言的细节将会被隐藏);
-
Instruction set architecture (指令集): the interface between hardware and lowest-level software;
-
Many implementations of varying cost and performance can run identical software.
-
高级编程语言
-
汇编语言
-
机器语言 eg.1000110010100000 指的是将两数相加.
-
-
Integrated Circuit Cost (集成电路成本)
Yield(良率): proportion of working dies per wafer ( 晶圆上能正常工作的芯片比例 )
\(\text{Cost Per die = }\dfrac{\text{Cost per wafer}}{\text{Dies per wafer}\times \text{Yield}} \quad \text{每个芯片的成本} = \dfrac{\text{每个芯片的成本}}{\text{每个晶圆的芯片数量}\times \text{良率}}\)
\(\text{Dies per wafer} \approx \dfrac{\text{wafer area}}{\text{Die area}} \quad \text{每个芯片的成本} = \dfrac{\text{晶圆面积}}{\text{芯片面积}}\)
\(\text{Yield = }\dfrac{1}{(1+(\text{Defects per area} \times \frac{\text{Die area}}{2}))^2} \quad \text{良率 = }\dfrac{1}{(1+(\text{缺陷密度} \times \frac{\text{单个芯片面积}}{2}))^2}\)
COmputer Performance¶
-
Response Time and Throughput
- Response time/ Execution time: 响应时间/执行时间,完成任务所需时间
- Throughput (bandwidth): 吞吐率
- 影响因素:增加处理器数量;用更快的处理器
-
Relative Performance
定义\(\text{Performance} = \dfrac{1}{\text{Execution time}} \Longrightarrow \dfrac{\text{Performance}_X}{\text{Performance}_Y} = \dfrac{\text{Execution time}_Y}{\text{Execution time}_X} = n\)
-
Measuring Execution Time:
-
Elapsed Time: 总回复时间
-
CPU Time: 对固定任务的总处理时间, 由User CPU time 和 System CPU time构成.
\(\text{CPU time} = \text{CPU Clock Cycles} \times \text{Clock Cycle time} = \dfrac{\text{CPU Clock Cycles}}{\text{Clock Rate}}\)
-
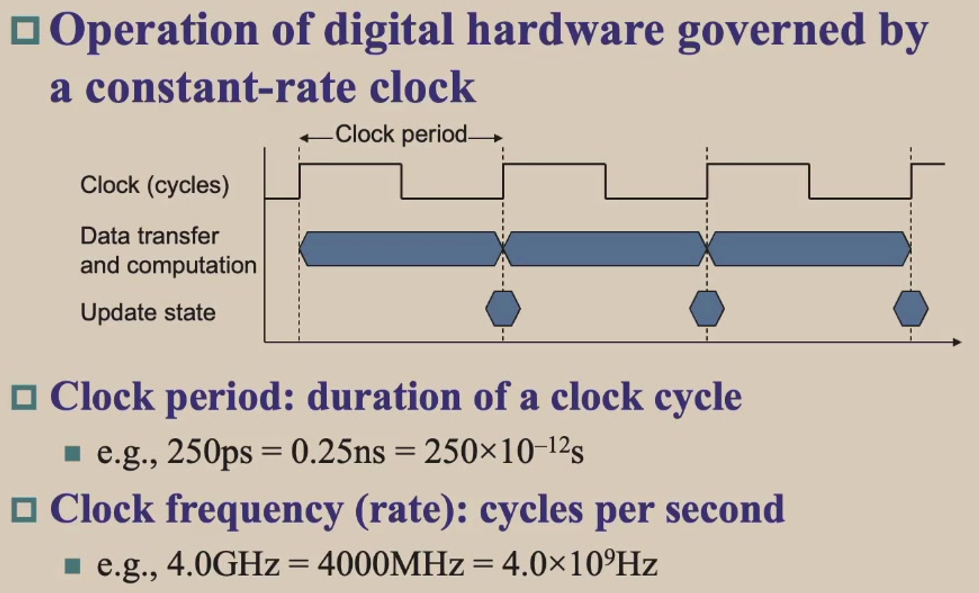
时钟周期:
-
Performance can be improved by reducing number of clock cycles or increasing clock rate. Hardware designer must often trade off clock rate against cycle count (为了提升性能,硬件设计师经常需要在时钟频率和周期数之间做权衡取舍).
-
-
IC(Instruction Count) and CPI(Cycles per Instruction)
IC取决于指令集架构. 如果指令集架构相同,那么IC也相同.
CPI是每条指令的平均周期数,大小取决于内存系统、处理器结构等设计细节.
\[\text{clock cycles} = \text{instruction count} \times \text{cycles per instruction}\]\[\Longrightarrow \text{CPU time} = \text{instruction count} \times \text{CPI} \times \text{clock cycle time} = \dfrac{\text{instruction count} \times \text{CPI}}{\text{clock rate}}\]简记:
\[\text{CPU_T} = \text{IC} \times \text{CPI} \times \text{cct} \quad \text{cc} = \text{IC} \times \text{CPI} \]如果CPU执行多种类型的指令,上面的公式修正为加权模式:
\[\text{CPU Clock Cycles} = \sum\limits_{i = 1}^n (\text{CPI}_i \times \text{Instruction Count}_i)\]对性能的概括:
\[\text{CPU Time} = \dfrac{\text{Instructions}}{\text{Program}} \dfrac{\text{Clock Cycles}}{\text{Instruction}} \dfrac{\text{Seconds}}{\text{Clock Cycle}}\]影响因素:
-
算法,影响IC,可能还会影响CPI;
-
Programming Language,影响IC和CPI;
-
Compiler,影响IC和CPI;
-
ISA,影响IC,CPI,\(T_C\);
-
-
阿姆达尔定律(Amdahl's Law)
用于计算系统某一部分性能提升后对整体性能的影响。
\[T_{\text{improved}} = \dfrac{\text{improvement factor}}{T_{\text{affected}}} + T_{\text{unaffected}}\]系统整体性能的提升受限于系统中未被改进部分的性能. * MIPS: 百万指令数每秒(Millions of Instructions Per Second, MIPS)
\[\text{MIPS} = \dfrac{\text{Instruction Count}}{\text{Execution Time}\times 10^6 } = \dfrac{\text{Instruction Count}}{\dfrac{\text{Instruction Count} \times \text{CPI}}{\text{Clock rate}} \times 10^6} = \dfrac{\text{Clock Rate}}{CPI \times 10^6}\]MIPS的局限性:不考虑不同计算机间ISA的差异,也不考虑指令间复杂度的差异,所以在考虑计算机性能时需要参考别的参数.
CPU固定时,如果程序不同,CPI也可能会不同.
-
Eight Great Ideas (摘编自mem的笔记)
-
Design for Moore's Law
这意味着超前设计,为了终止时的情形设计而非刚开始时
摩尔定律(Moore's Law):单芯片上所集成的晶体管资源每 18 至 24 个月翻一番。
-
Use Abstraction to Simplify Design:
通过抽象化来简化设计,使设计更易于理解和管理。
采用层次化、模块化的设计。
-
Make the Common Case Fast:
加速大概率事件
如部分指令集设计中的 0 号寄存器。
-
Performance via Parallelism:
通过并行提升性能。
-
Performance via Pipelining:
通过流水线提升性能。
换句话说就是,每个流程同时进行,只不过每一个流程工作的对象是时间上相邻的若干产品;
相比于等一个产品完全生产完再开始下一个产品的生产,会快很多;
希望每一个流程的时间是相对均匀的;
-
Performance via Prediction:
通过预测提高性能。
例如先当作 if() 条件成立,执行完内部内容,如果后来发现确实成立,那么直接 apply,否则就再重新正常做。 这么做就好在(又或者说只有这种情况适合预测),预测成功了就加速了,预测失败了纠正的成本也不高。
-
Hierarchy of Memories:
不同类型的存储器具有不同的速度和容量,不同层次使用不同类型的存储器以提高性能并节约成本。
从底层(Bigger,slow)到顶层(Smaller,fast):
Disk / Tape -> Main Memory(DRAM) -> L2-Cache(SRAM) -> L1-Cache(On-Chip) -> Registers
-
Dependability via Redundancy
通过冗余设计来提高系统的可靠性,确保单点故障不会导致系统崩溃。
-
Tips
1.2 计算机体系结构中的八个伟大思想与其他领域的思想相似。请将计算机体系结构中的八个伟大思想——“面向摩尔定律的设计”“使用抽象简化设计”“加速经常性事件”“通过并行提高性能”“通过流水线提高性能”“通过预测提高性能”“存储器层次”“通过冗余提高可靠性”与其他领域的下列思想进行匹配:
a. 汽车制造中的组装生产线\(\Longrightarrow\) Performance via Pipelining
b. 吊桥缆索\(\Longrightarrow\)Dependability via Redundancy
c. 采用风向信息的飞机和船舶导航系统\(\Longrightarrow\)Performance via Prediction
d. 高楼中的高速电梯\(\Longrightarrow\)Make the Common Case Fast
e. 图书馆的存阅处\(\Longrightarrow\)Hierarchy of Memories
f. 通过增大 CMOS 晶体管的栅极面积来减少翻转时间\(\Longrightarrow\)Performance via Parallelism
g.增加电磁飞机弹射器(不同于当前的蒸汽驱动模型,它采用电驱动),这可以通过新型反应堆技术增加的电能来实现\(\Longrightarrow\)Design for Moore’s Law
h.制造自动驾驶汽车,其控制系统是安装在汽车上的传感器系统。例如车道偏离检测系统和智能导航控制系统\(\Longrightarrow\)Use Abstraction to Simplify Design