如何提高自制力?
本文系转载,这是知乎原文链接
我期待这篇文章成为迄今为止(2025年)中文互联网上,在自制力话题下最硬核的技术讨论,没有之一。
或许这个目标稍显大胆,但读者诸君倘若对此感到保留,请允许我邀请你快速滑动一下,感受一下本文的风格和内容,或许能稍稍增加你的一点信心:)
在这篇文章中,我想传达的核心思想是:自制力问题,未必只能是一个心理学或生理学问题,或许也可以是一个能用数学、物理学去解决的工程问题——基于上述理念,存在这样的可能性:人可以在没有DDL、环境约束,甚至任何外界监督的情况下,仅凭几个抽象而精妙的思想实验,即可对自身行为施加持久而深远的约束力,甚至在一定程度上改变整个生活的长时间稳态。
(当然,需要特别说明的是,即便再强大的方法论也只能部分地解决行为问题,许多严重的神经性、病理性问题仍需诉诸专业的医学途径来处理。)
为了验证这个想法,笔者作为一个从小被严重ADHD和自控问题困扰的人,花费了从小学到博士的十几年岁月,经历了无数试错,思考和验证,才逐渐摸索出这篇文章将要介绍的两代自控技术。
它们曾帮助我,在没有外界约束和药物治疗的条件下,完成从长期挣扎却无法专注哪怕一个小时,到可以连续几个月在没有外界压力下在家全天专注自习,生活状态井井有条的蜕变。这两代技术的探索过程,也是对“自制力”这个现象不断试错与迭代的,有趣而曲折的旅程。
所以,我一直将写下这篇文章,当作一件必须完成的心愿:我希望把它们作为礼物,送给那些和曾经的我一样,被ADHD和自控障碍折磨的人们。亲爱的陌生人啊,惟愿它能帮助到你们,以及其他正在受苦的人,哪怕只是解决一点点因自制力问题而带来的烦恼。
接下来,我会慢慢把这两套方法讲给你听。它们分别叫做 CTDP(链式时延协议) 和 RSIP(递归稳态迭代协议)。这两套方法的思路与目前常见的强调“放下手机”、“制定计划”、“目标分解”、“奖惩机制”、“延迟满足”、“内驱力”、“习惯打卡”等概念的俗套讨论迥然不同。
——我想做的,是从日常行为中抽象出底层的数学与物理机制,尝试从第一性原理出发,尽可能优雅地(部分)破解拖延,启动困难,中途放弃,状态低迷这些人类千百年来的自制力难题。
当然,在这个过程中,我会引入一些基本的数理概念,要彻底理解可能需要一点大一高数的基础。但请放心,我会尽力使用通俗易懂的科普语言,以定性和半定量的方式作概念性解释(定量分析对这个主题也不现实)。此外,为了让更多和我一样有注意力障碍的朋友能顺利读下去,本文还将采用对ADHD更友好的口语化写作,配合图文穿插,并采用带有数字编号的分段方式进行组织。
最后,一个小提示:在阅读过程中,你很可能会产生各种各样的疑问(比如读到神圣座位原理时,可能会想“如果作弊怎么办”、“如果反而不愿坐上去怎么办”),请千万不要着急,通常下一节就会解答这些疑问。而第一代方法的许多局限性,也会在第13节后引入的第二代方法中讨论与解决。总之,请慢慢读,千万别着急:)
1
在正式讨论之前,让我们来考虑一个最常见的场景:
假如现在是晚上七点,你刚吃完晚饭,坐在书桌前,面前是计划要完成的作业或一份想读的paper。与此同时,你的手机屏幕亮了,你瞥见小红书上一个有趣的推送。此时,摆在你面前的有两种选择:
- 玩手机:你会得到即时的放松和快乐,然而,这看上去有可能耽搁你今晚的学习计划,事后可能会产生焦虑和愧疚;
- 去学习:你会面对即时的枯燥和疲惫,然而,这将缓解你最近的任务压力,对学业也有帮助。
而在这个选择面前,几乎所有自制力短缺的人都会倾向于刷一晚上视频,然后悔恨不已,这到底是为什么呢?
这个问题,就是自制力问题下最经典的toy model。针对它,人们提出了各种各样的讨论,所谓意志力模型,多巴胺,奖惩机制,目标分解,延迟满足,环境控制,心理暗示,身份认同,to do list等无数的学术概念,经验法则,民间偏方云云。
然而,在本文中,我将摒弃所有上述老生常谈的,模糊的概念,而是用一个简洁的数学模型去解释。
2
这就是本文的第一个断言:人在面临任何选择时,对某个行为的真实倾向,都必然可以表示为该行为的未来价值函数 $V(\tau)$ ,和权重贴现函数 $W(\tau) $的乘积,从当下这一刻($\tau=0 $)到无穷远处的积分:
$ I=\int_0^{\infty}V(\tau)⋅W(\tau)\mathrm{d}\tau $
其中:
- 未来价值函数 $V(\tau)$ ,表示当前的你眼中,该行为在未来每个时刻$\tau$ 带来的价值;
- 权重贴现函数$W(\tau) $,则表示你对未来每个时刻 $\tau$ 的价值重视程度(经济学上的双曲贴现函数也描述了类似现象)。
换言之,我们面对选择的时候,并不是把所有“未来的价值”加在一起再决定,而是取决于未来所有时刻的价值加权总和,一般来说,眼前的价值权重更高,而未来的价值权重则更低。
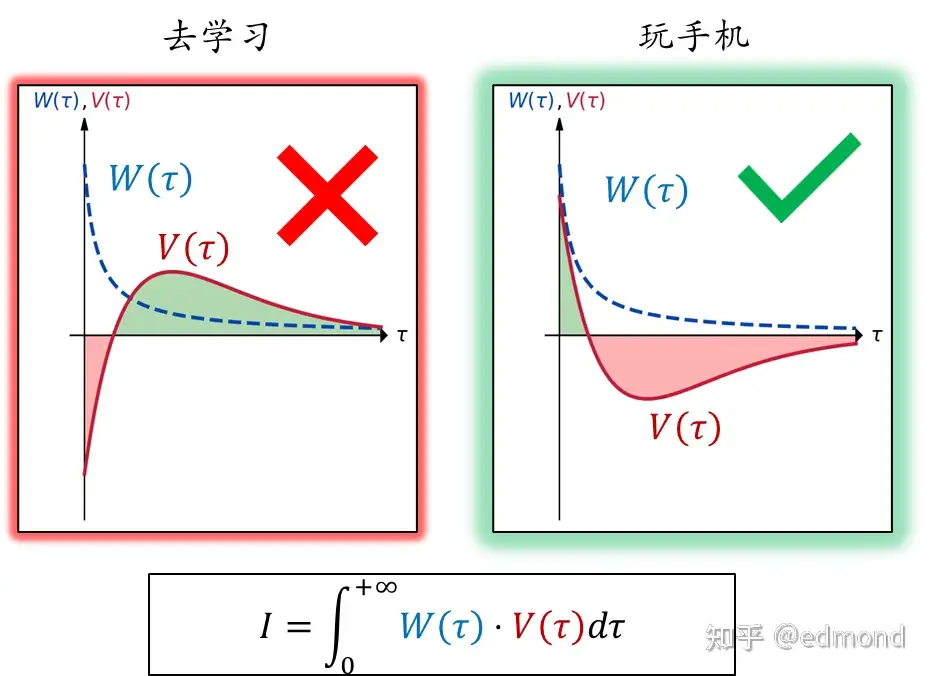
就拿刚才那个“去学习 vs. 刷手机”的例子来说:
- 如果选择去学习,短期我们要面对切换成本与学习的枯燥,因此$V(\tau)$ 为负;但中期因学习缓解的压力和满足感$V(\tau)$转为正;而在更远的未来,一次学习带来的影响终究会逐渐消散, $V(\tau) $又趋近于0;
- 而刷手机则相反:短期即时愉悦使得$V(\tau)$为正,中期却会因耽搁计划产生焦虑和愧疚,$V(\tau)$ 转为负;而玩这一晚上手机也终究不会改变人生,于是$V(\tau)$也会慢慢趋于0。
理想情况下(也就是纯理性的情况),如果权重函数$W(\tau)$是恒定的常数,那么学习的净价值总量明显会高于玩手机。
然而,我们的大脑往往极度短视,权重函数 $W(\tau) $在短期非常高,而在长期迅速趋于零。
在这种短视的权重分布下,刷手机在短期上的优势乘以权重后占了大便宜,积分结果反而会远远高于学习,这就是我们最终会选择玩手机的原因。
(注:在本文中,我们对这两个函数采取“设而不求”的处理,只进行定性分析,毕竟定量分析在这个问题下并不现实)
3
事实上,你会发现,这个看似简单的数学模型,几乎能解释生活中所有类似的经典场景:
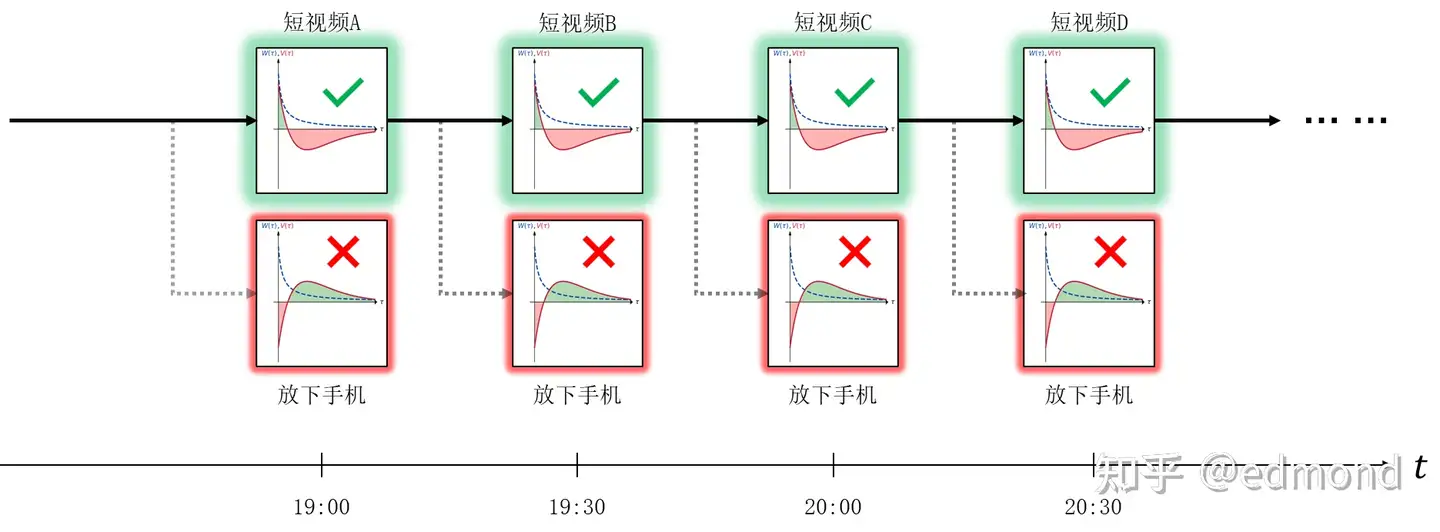
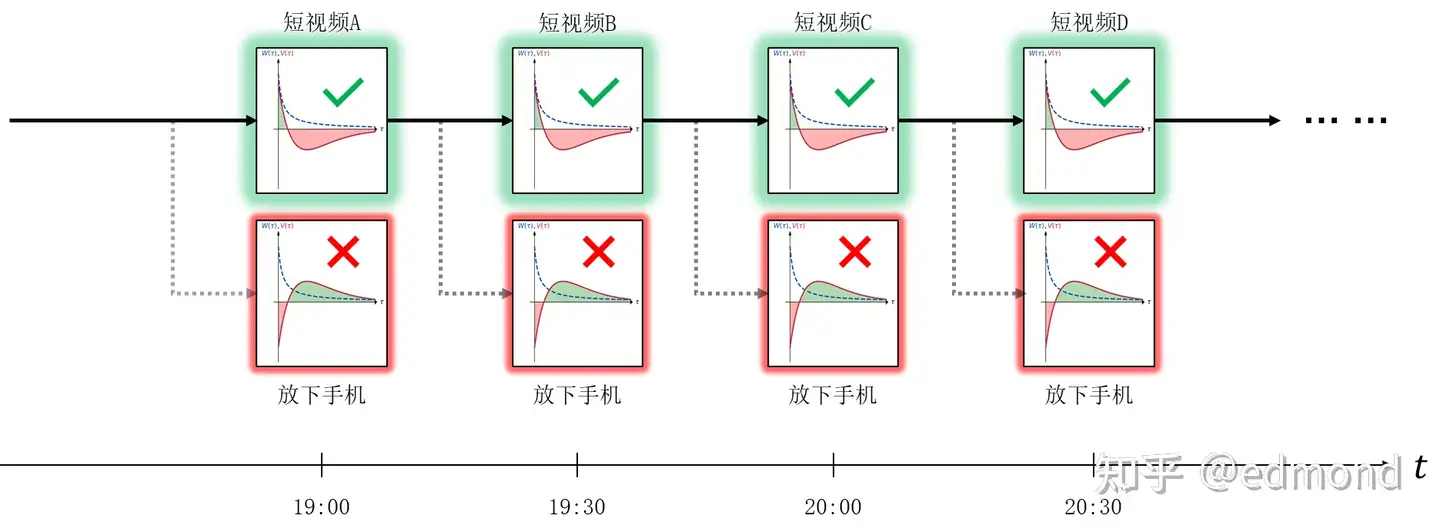
比如,还是刚才那个玩手机的例子。你最终选择了拿起手机,想着只玩一会儿,然后会发生什么呢?
从你拿起手机开始,同样的故事就会无限重复:
- 刷完短视频A,再刷短视频B的短期诱惑又会高于放下手机;
- 刷完短视频B,再刷短视频C的短期诱惑又会高于放下手机……
在每时每刻的你看来, 短视频放下手机$I(短视频)>I(放下手机)$都成立,于是你每时每刻都会选择再刷下一个短视频。
所以,你就这样刷了一整晚,直到凌晨两点,三点,晚睡的代价开始越来越可观,以至于慢慢抵消掉短视频带来的诱惑,你才终于充满悔恨地上了床。
(当然,也有一些人因为无法直面晚睡后的焦虑和自责,放下手机的心理代价越来越高,最终干脆熬了一整夜。)
但如果,你一开始选择的是去学习呢?你也许会惊讶地发现,一旦真正投入进去,继续学习反而会变得越来越轻松,你甚至渐渐觉得没什么兴趣去刷手机了。
这是因为心理学上的“切换代价”现象:当我们从一项任务切换到另一项时,这个“切换”本身就天然伴随着一定的心理阻力。在这个模型中也很好理解——想要从当前活动中抽身,你必须先把手头的动作停下来,清理大脑中已经加载的工作记忆,再强行切换到新的行为流程。
这个成本,在数学上就相当于在最敏感的 $\tau=0$ 位置,插入了一个负向的冲激函数!
这便是陷入放纵后也更难爬出来,但开始任务之后也更容易坚持的原因。
(为了后续表示更方便,我不会单独画出这个切换代价的冲激函数,而是自动将它合并到价值函数 $V(\tau) $中。)
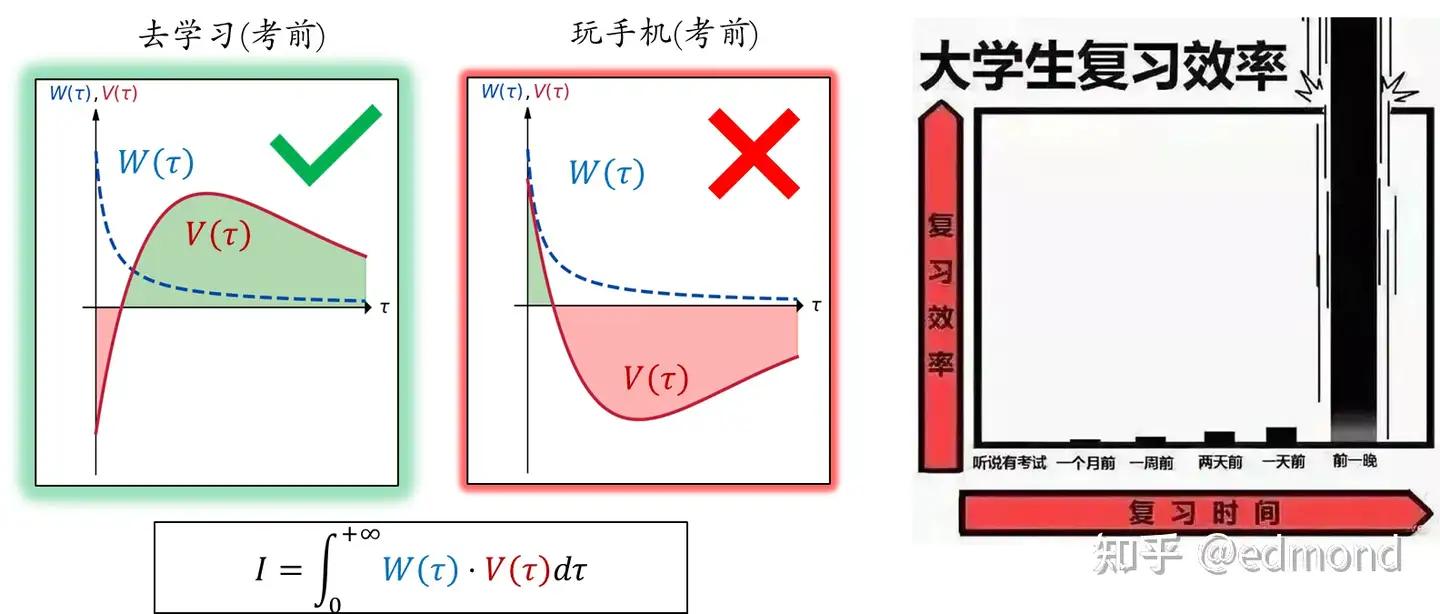
不过,有些时候我们也可以自然地抵抗玩手机的诱惑。考前复习周,DDL前夕就是这样的时候。
前面提到,平时刷手机带来的短期愉悦,通常只会在中期造成一些焦虑,并不会真正对我们人生产生重大影响。
但考试周可就不一样了——如果你此时还沉迷短视频,你就会挂科,产生一系列严重后果,搞不好真的就改变人生了。
于是,玩手机的远期负面价值急剧膨胀,硬生生地以极低的权重打败了短期诱惑!所以,复习周的剧本通常都是一个泾渭分明的阈值,到了某个时间点后,你的时间投入会突然陡增。所谓的”ddl是第一生产力“,其实也是这个原理。
(当然,对一些人而言,这种后果的严重性也会“去复习”承担的意义越来越沉重,切换代价提高,越接近ddl反而越无法开始,最后真的挂科了)
诸如此类的例子还有很多。可以说,在单一行为来看,我们的自控成败只取决于一件事——价值分布函数 $V(\tau)$ 在时间上的分布是否有利。
4
既然 $W(\tau)$ 代表的是人类与生俱来的“短视性”,它几乎是固定的,我们很难从根本上改变它。那么,我们要问一个问题:自控又是“如何可能”的呢?
这里,我们可以作出本文的第二个断言:
人类一切有效的自控策略,本质上都是在构造一种对价值分布函数的变换$V(\tau)→V’(\tau)$ ,从而使行为倾向更接近于理性决策的结果。
举几个例子:
- 没用的方法1(远期奖励) 自我激励、想象“未来成功后的美好生活”,或者搞“游戏化”,给自己设定学习完成后的奖励。这相当于在学习行为的价值函数 $V(\tau)$ 上,在远期叠加了一个正向的线性激励——但由于远期权重极低,这种方法其实吃力不讨好,通常没什么卵用;
- 没用的方法2(远期惩罚) 给自己设置玩手机的惩罚,或者玩手机后就去跑步,写检讨。这相当于给玩手机的价值函数 $V(\tau)$ 上,远期插入一个负值——这种方法同样没什么卵用;
- 稍微有用的方法3(近期惩罚) 把手机锁起来,或者找人监督。这相当于在近期提高放纵行为的切换成本,即对其 $V(\tau)$ 近期插入负值——这种方法有用,但不多;
- 有用的方法4(非线性压缩) 比如很多人都熟悉的“番茄工作法”。其机理实际上是在学习开始后,变换“中途放弃”的 $V(\tau)$ ,将整个番茄钟的沉没成本打包、捆绑,然后非线性压缩到当下的一刻——这是比较有用的方法,在后面讲解 CTDP(第一代技术)时,我们会对其进行详细展开。
为了更直观地衡量这些方法的有效性,我们还可以定义一个指标,那就是自控策略的增益($G$):
学习放纵学习放纵$G=\frac{I’(学习)}{I’(放纵)}/\frac{I(学习)}{I(放纵)}$
简单来说,就是使用策略前后的理性决策倾向之比。如果用这个指标去检验市面上绝大多数主流的所谓“自控方法”,你会发现,它们的增益普遍低得可怜。要么仅仅在权重极低的远端做文章,要么甚至根本就不作用于价值函数 $V(\tau)$ !
比如“Just do it”,“告诉自己,你始终是有选择的!”之类的营销号励志口号,这种玩意居然还能在知乎、抖音上获得成千上万的点赞,可见当前关于自控话题的平均认知水平之低。
而那些能靠低效手段实现自控的人(这些人很多确实优秀),并非因为这些方法多么出色,而是因为他们本来就有优质的习惯、环境、自身条件,距离真正自控只差临门一脚,所以哪怕微弱的刺激也能推动他们实现正向行为。
可悲的是,正因为这些优势在个人成就中其实占据了极高的比重,拥有这些优势的人反而很少需要追求真正高效的自控策略。他们在成功后分享的那些肤浅方法,反而成了最广泛传播的主流认知——这种反直觉的幸存者偏差,我们将在文章末尾进行更深入的讨论。
5
接下来,有趣的事情来了。
有了这个数学基础,我们可以构造出一个极其巧妙的策略,通过在不同时间点上对 $V(\tau)$ 进行非线性压缩和线性平移变换,来近乎凭空地,为单个理性行为套取惊人的正向增益。
更重要的是,它能够一举破解我们在自控中最常见的三个顽疾:启动困难,中途放弃和三分钟热度。
而这一切,都建立在三个核心原理上。
第一个核心原理,叫做“神圣座位原理”。
我们不妨做这样一个思想实验:
假如某个自习室里,有许多座位供你自由选择。有一天,你突发奇想,指定其中一个座位为“神圣座位”,并为它制定了这样一条游戏规则:
坐在其他任何座位上,都没有特别的约束,你想干什么都行;但只要你的屁股一旦碰到这个“神圣座位”,你就必须用最好的状态,100%专注地学习满一个小时。反过来,如果没有自信做到专注,那么就干脆不允许自己坐在这个座位上,宁愿选择其他普通座位。
总之,这个“神圣座位”决不允许被不专注的屁股所玷污。
当然,仅仅是随便想象这样一条规则,本身并不具备什么真正的约束力。但是,假如你真的认真执行了一次呢?
某一天,你真的坐了上去,屁股一沾到那个座位,你就真的用最认真的状态学习了一个小时。
神奇的事情发生了:从你第一次成功执行这条规则的那一刻起,这个原本只是想象出来的座位,就真的在你心中被赋予了价值!此后,你大大咧咧地坐在这个座位上玩手机的可能性,就真的会远低于之前的情况!
这时候,你再加入一个新的游戏规则:
把第一次专注的纪录记为#1,此后每次花一个小时专注成功,都可以作为工作量证明,为这个“神圣座位”增加一个编号记录:#1、#2、…、#N。 但只要有一次失败——比如你在上面刷了手机,或者只坐了十分钟就走人——那么所有纪录都会被清零,下次只能重新从#1开始。
**随着这个链条不断延长,工作量证明不断积累,这个虚构的座位的价值会一次次地增强。当这个“专注任务链”增长到 **#10、#20、#30的时候,这个规则的约束简直就要实质化了——你甚至可能变得谨小慎微,连大气都不敢出,生怕有一丝一毫对规则的不敬。
(聪明的你肯定想到了这个规则可能崩溃+你不愿意坐上去的问题,别急,这正是8,9节要解决的)
(为了避免很多人的误解,这里需要声明,这并非最终版的方法,真正起作用的是数学机制,和所谓“道德”‘仪式感’“心理暗示”“now or never”没有半毛线关系,后面会详细解释)
6
这种神奇的约束力,实际上是来源于人类对“保持纪录”这件事情与生俱来的执念。
许多健身或学习类App都设有“连续打卡”功能。很多人即使再困再累,也要勉强背5分钟单词,只为了维护Duolingo上那条“365天连续签到”的纪录;戒烟戒酒连续坚持了10天的人,看到10天这个数字,也会比刚开始的第1天时更难放弃。
——仅仅是一个想象出来的纪录,就足以产生近乎荒谬的约束力。
细究起来,这种约束力其实来源于两点:
- 一方面,纪录保持越久,你为维护这个纪录所付出的真实时间、精力也就越多。链条上每一个成功的任务节点背后,都是真实的“工作量证明”和沉没成本;
- 另一方面,这种纪录往往还伴随着一个妙不可言的“未来价值预期”:你认为这个纪录有价值→你害怕失去这个纪录→它就会产生约束力→这个约束力又有助于你未来的自控,你以后的自控就仰仗它了→这个纪录更加有价值。 价值越高,约束力越强;约束力越强,未来预期越高;未来预期越高,价值越高……
然而,所有的”纪录“,都天然带有“一损俱损”的特性:一旦你打破了这个纪录,所有这一切辛苦积累的沉没成本和未来预期,都会立即,突然地在 $\tau=0$ 的瞬间彻底失去!
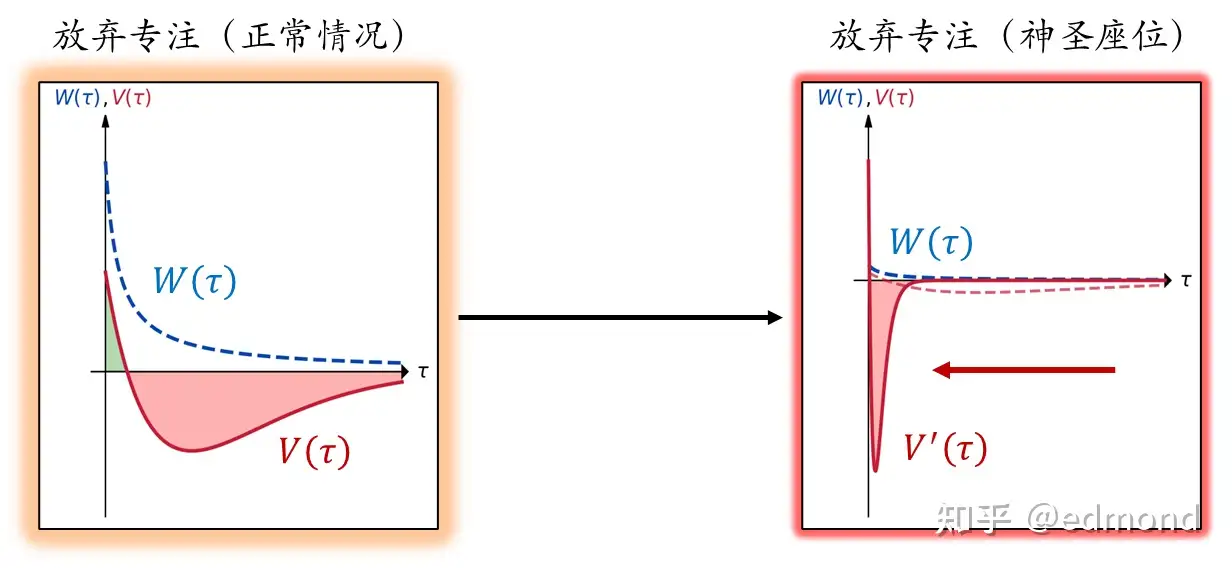
这便是“神圣座位原理”的背后数学本质:对 $V(\tau)$ 的非线性压缩变换。
当你坐在这个座位上时,整个任务链所有节点过去投入的价值,和未来的预期价值,就会在“放弃专注”这个选项的价值函数中,被急剧地压缩,凝聚成一个极度接近原点( $\tau=0$ )的负向尖峰——任何对规则破坏的短期诱惑,事实上都要立即面对全链已积累和未来价值的挑战。
而最妙的是,这一点在专注任务的每一刻都持续成立。当沉没成本积累到一定程度时,就再也不会有任何短期诱惑能够挑战这样一个惊人的屏障了。
7
这种“一损俱损”的价值捆绑原理,也是很多经典自控策略真正起作用的原因:
比如番茄工作法,每一个番茄钟实际上相当于一个“小号的神圣座位”:它把整个专注时段的沉没成本和未来预期,打包、捆绑在了一整颗“番茄”里。一旦你在番茄钟期间懈怠或放弃,你立刻就要在当下瞬间承受失去整颗“番茄”带来的巨大代价。
这样一来,你每一刻的选择权衡,不再是“眼前诱惑与当下任务”之间的比较,而是变成了“眼前诱惑与整颗压缩后的番茄总价值”之间的竞争——这才是番茄工作法背后真正有效的核心机制。
再比如,很多人也有过这样的体验:
你某天学到了一个全新的自控方法,觉得非常有道理,于是兴致勃勃地投入了实践。在一开始,哪怕那个方法实际上毫无卵用,你都会发现它如有神助。
但奇怪的是,过了几天之后,最初的新鲜感逐渐消退,你开始频繁违规,方法的有效性迅速衰减,最终彻底失效、被你抛弃。
这就是一种类似“新手保护期”的错觉:任何自控方法在前几天看上去都是有用的,但真正起作用的可能并非方法本身,而是你对这个方法的“未来预期”。
当你将未来自控的希望寄托于这个方法时,这个“寄托”便短暂地,真的赋予了它约束力。然而,如果方法本身低效,这种临时的约束力终究无法支持它在复杂的真实环境中长期存活,一旦出现任何一次违规或磨损,整个方法的信誉和价值就会随着破窗效应迅速崩溃。
而“神圣座位”这个设计最美妙的一点,就是它在时间上天然是一种分布式的、去中心化的设计。它只对坐在那个座位上的,精选过,提纯过的状态负责,而无需暴露在所有时间中,对长期状态负责,从而最大化地避免了磨损。
换句话说,你可以在满状态下完成了#1号任务之后,去聚餐、喝酒、打游戏,荒废几天乃至一个星期,但当你下次重新走进自习室开始#2的时候,神圣座位依然是那个神圣座位,它的约束力丝毫不会减弱。
8
当然,即便在这个精选的状态中,“神圣座位原理”也并非完全没有漏洞。
前面说到,一旦坐上这个位置,就要以“最好的状态”专注学一个小时。那么问题来了,怎么去定义这个“最好的状态”呢?
- 如果我中途去上厕所,还算不算“最好的状态”?
- 如果我接个电话,去拿个快递,还算不算“最好的状态”?
- 如果有人发消息找我,我回复一下,还算不算“最好的状态”?
- 如果这些都算,我中途玩玩手机,刷两下短视频,也可以算“最好的状态”吧?
你会发现,“理想状态”根本就不存在,任何自控策略一旦进入实战,都必须面对复杂多变的真实情况。表面上,一个自控策略只是一个简单的约束;但实际应用时,所有的自控策略都等价于大量隐含的,微小的“子约束”,每个子约束都可以被考验、被挑战:
- 如果你允许自己灵活地自由裁量,那方法的约束力就会在一次又一次“这次特殊,下不为例”的侥幸心理中不断磨损,产生破窗效应,最终被腐蚀得千疮百孔;
- 但如果你完全不允许任何例外,这个方法就会变得刚强易折,当你遇到一次忍无可忍的情况时,规则便可能瞬间、彻底地崩溃。
这种“渐进破窗效应”,正是绝大多数类似于“游戏化”或“设立规则”的方法迟早都会失败的根本原因。运动员玩什么游戏不重要,把运动员和裁判分离的逻辑才重要。
为了解决这个问题,让我们引入更加精妙的第二个核心原理:“下必为例”原理。
(注意,是下必(bì)为例,不是下不(bù)为例)
既然你自己也清楚,只要有了第一次“下不为例”,就必然会产生无数次后续的耍赖行为。那么,不如反其道而行之,强制要求自己“下必为例”——也就是说,反过来要求自己以后必须耍赖!

具体而言,当你面临任何疑似违规的判定时,就像西方法律体系里的“判例法”一样,只能在下面两个选项中选择一个:
- 立即判定这个“神圣座位”的规则被完全破坏,链条断裂,彻底清空所有任务纪录,承认约束力完全归零;下次老老实实从 #1 重新开始;
- 判定这个行为允许,但是,只要这一次允许,未来遇到同样情况也必须一律允许,在这个任务链接下来的整个生命周期,它都会彻底失去对该行为的约束力。
你的“最好的状态”,并不是由任何主观或客观的标准定义,而是由无数个“判例”,去动态地形成定义:
- 中途去个厕所,还算不算“最好的状态”?可以算,但只要这次算,以后就必须都算;
- 中途回复消息,还算不算“最好的状态”?可以算,但只要这次算,以后就必须都算;
- 中途刷两分钟短视频,还算不算“最好的状态”?可以算,但只要这次算,以后就必须都算;
这样一来,你考量的就不再是一次孤立的选择,而是要不要在当下这一瞬间,永久地放弃掉这个规则对该行为的约束力。摆在你面前的代价,便是允许这个行为的真实长远代价。
现在在你眼中:
- 对于理智上本就不该允许的行为(例如玩手机),坐在座位上的你非常清楚:只要今天允许了这个“例外”,那么未来每一次坐上这个座位,你都会援引这次行为作为“先例”来耍赖(况且规则要求你必须耍赖),再也无法重新把这个行为定义为违规;
- 而对于理智上本来就应该允许的情况(例如上厕所),未来的你也能心安理得地给自己放行,不会对规则的信誉有丝毫顾虑。
最终,你所作出的判决就真的成了最符合长期理性的决策。因为,为当下着想的你(作为运动员),和为未来着想的你(作为裁判),已经在这种机制下奇妙地达成了共识——就这样,你自己和自己,达成了跨越时间的纳什均衡。
当这个方法长期运行下去,规则的约束边界并不会像传统方法那样逐渐腐蚀、崩溃,而是缓慢地、 $\epsilon-n$ 式地,以一种“永远刚好够用”的精度,逐步收敛到最接近理性决策的边界上:既能容许真正必要的例外,又能有效防止非必要的自我放纵。
这就是“下必为例”原理的精妙之处。
9
好了,现在我们有一个完美的“神圣座位”了。但一个新的问题随之而来:
越神圣的座位,你反而会越不敢坐上去。
的确,坐在这个“神圣座位”上的状态非常完美。然而,这个座位太神圣,太完美,以至于“坐在座位上”这个动作的承诺太沉重,你会越来越不愿意坐上去,也就是常说的“启动困难”问题。
这正是为什么人们总喜欢说“完美主义导致拖延症”(其实严格来说,拖延症的本质并不是完美主义,而是过高的预期造成的切换成本上升)。
此时,就要轮到我们第三个核心原理:“线性时延原理”。
而这个原理,从数学的角度看,可以以一种优雅的方式,一击破解长期以来困扰无数人的“拖延症”难题。
让我们再做一个简单的思想实验:
- 假设你找到一个典型的拖延症患者,问他:“你愿不愿意此刻立刻开始学习?”他多半会摇头拒绝;
- 但如果你换个方式问他:“那你愿意明天下午再开始学习吗?”甚至不用等那么远:“15分钟后再开始怎么样?”这一次,他居然多半会表示同意!而且,这个时延越长,这个人表示同意的概率就越高。
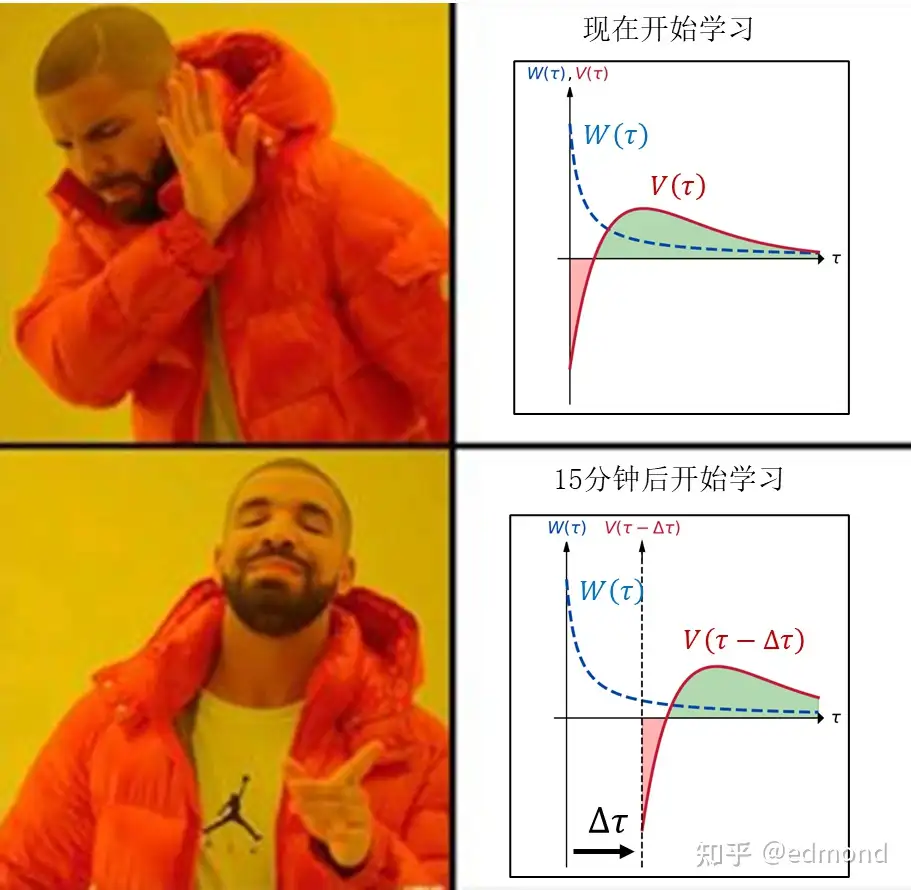
为什么会出现这个奇特的现象呢?
我们不妨再次回到前面的数学模型来解释一下:
- 当你考虑“是否现在立刻开始学习”时,正如前面分析的那样,价值函数 $V(\tau)$ 的负面价值恰好处于权重函数$W(\tau) $的高权重的近期,因此你会感到强烈的抵触;
- 然而,当你考虑“是否愿意15分钟后再开始学习”时,情况就完全不同了:这实际上相当于将 $V(\tau)$ 在时间轴上向后平移了15分钟,到了 $W(\tau)$ 相对平坦的区域!和放纵的选项相比,这就几乎抹平了它在短期的巨大劣势。
这也解释了日常生活中非常普遍的一种现象:我们总是对未来的自制力抱有盲目乐观的幻想。
在双曲贴现函数中,权重随着时间的下降是先陡峭,后缓慢的——10分钟后的权重和1小时后的权重可能天差地别,然而1天零10分钟后的权重,和1天零1小时后的权重则几乎相差无几。
当我们提前考虑未来的选择时,就相当于用 $V(\tau-\Delta\tau)$ 平移后再和 $W(\tau)$ 积分,平移的距离越长,实际参与积分的 $W(\tau)$ 就越平缓,自然也就越接近理性状态。这就是我们在制定暑假计划时经常盲目乐观,拿起手机时天真地以为自己真能刷五分钟就放下的原因。
而这个方法最高潮的部分来了:
我们可以在主任务链之外,再额外建立一个平行的“辅助链”,同样也被神圣座位原理保护,同样对所有情况都”下必为例“,而它所捍卫的约束规则非常简单:
- 设定一个简单的动作作为预约信号,比如打一个响指;
- 一旦触发这个信号,你就必须在接下来的15分钟内—— 坐!到!那!个!神!圣!座!位!上!去!
所谓堵不如疏,克服拖延的最好方法,就是首先承认并尊重拖延。
既然”预约15分钟后开始“的阈值,远低于”立即开始“的阈值,现在的你便毫无压力地启动了预约。
15分钟后,那条辅助链过去和未来的价值,就会渐渐在$\tau=0$ 处压缩、凝聚成一根尖锐的,突破天际的撞针——硬生生地刺开那道“切换成本“和”启动困难“的大门。
(顺带提一个囧事:刚想出这个方法的时候,有一天晚上睡不着觉,不小心打了个响指,只能无奈凌晨三点爬起来学了一个小时)
现在,结合前面的三个核心原理,我们终于得到了完整的第一代自控技术:
链式时延协议(Chained Time-Delay Protocol, CTDP)
10
以下就是链式时延协议(CTDP)的完整表述:
CTDP 是一种基于三个核心原理(神圣座位原理、下必为例原理、线性时延原理)构造的行为约束策略。具体来说,它要求你构建两条平行的任务链(主链和辅助链),并且严格按照以下步骤进行:
Main Chain 主链(任务链):
-
首先,指定一个具体的事物作为标志,作为”神圣座位“(事实上,神圣座位只是一个比喻,它可以是任何事物,一张特定的椅子、一支特别的笔、一顶帽子,甚至是发给你特定微信小号的一条消息都可以)
-
一旦你触发了这个标志,你就必须以“最好的状态”完成一个明确的专注任务;
-
每当你成功完成一次专注任务,就可以在主链中记录一个节点:第一次成功为 #1,第二次成功为 #2,第三次为 #3,依此类推;
-
如果在任何一次任务中途,你似乎做出了与”最好的状态“不符的行为,必须在下列两个选项中选择其一(“下必为例”原则):
-
- 判定整个主任务链立即失败,清空所有当前已累积的节点记录,下一次只能从 #1 重新开始;
- 判定允许当前行为,但从此以后,该行为在后续任务中也必须永久允许,不得再视作违规;
Auxiliary Chain 辅助链(预约链):
-
定义一个简单的预约信号,比如打一个响指、打开一个闹钟,表示15分钟后将开始主任务;
-
一旦你触发这个预约信号,在接下来的15分钟内,你必须去触发那个神圣座位对应的标志,开始一个主链任务;
-
如果在预约触发后,你没有在15分钟内触发那个标志,那么同样适用“下必为例”原则:
-
- 要么彻底清空预约链的纪录,承认预约链失败;
- 要么允许当前的情况,但从此以后预约链将彻底失去所有对该情况的约束力;
至此,我们通过同时使用非线性价值压缩(神圣座位)+ 判例法约束(下必为例)+ 线性时间平移(预约机制)的三重巧妙机制,Hack掉了启动困难、破窗效应以及短视决策的影响。
仅靠几个思想实验,我们就构造出了一种在没有外部监督,甚至意志力不足的条件下,近乎凭空地为理性行为套取巨大增益的自控策略。而且,其约束力完全源于每个节点的工作量证明,只对这些分布式的精选节点负责,不会暴露在长期状态波动中而受到腐蚀。
依靠CTDP这个策略,我们对任何重要任务,都可以做到既容易开始、又容易坚持,长期还不会失效——这看似不可能的三角,我们全都要。
11
当然,前面讲述的CTDP更多是理想化的版本,现实生活中,它的应用远比刚才讲的要更加灵活有趣。
比如说,“神圣座位”真的一定要是一张座位吗?
其实并不一定,它可以是任何具体的、容易区分的标志。比如我自己平时用的标志便是一个专门的微信小号,每次开始任务时就发一条消息,用来触发任务,同时也记录节点和目标声明;
CTDP表面的画风
其次,任务链本身也不一定非得是严格的线性推进(#1、#2、#3……),你完全可以构造一种自上而下的层级组织:
- 比如说,三个单元级节点,可以组成一个3小时的任务组,记为##1;
- 三个任务组,组成一个日级的任务群,记为###1;
- 三个任务群,组成一个三日级别的任务纵队,记为####1;
- 两到三个纵队,又可以用一个周级任务集群来管理,记为#####1;
而每个单位,都可以有自己的要求,例如##任务组可以要求前两个#单元完成后都执行一次预约信号,就可以把三个#单元串起来了。 这样一来,我们就像军事指挥序列一样,以一种”三三制“的方式,把庞大的任务链自上而下地组织了起来!
同样,任务单元的内容也不一定都是单调的专注学习,中二地来说,它还可以分成不同的”兵种“。
比如,学习,做实验、读论文=”突击单元“,信息搜集=”侦查单元“,制定计划=”指挥单元“,处理杂事=”特勤单元“,运动锻炼=”工程单元“,备餐做饭=”炊事单元“……
而一个大的任务群,任务纵队,又可以像现代合成部队一样,由多个兵种组合而成——
一个专注于工作的主战任务群,可以由7个突击单元+2个侦查单元合成;
一个周末休整的后勤任务群,可以是1个指挥单元+3个特勤单元+2个工程单元+1个炊事单元的合成;
在假期,一个兼顾运动和自学的三日级纵队,又可以按6突击组+3工程组合成。
CTDP实际的画风
你会发现,这个任务链结构就这样自然地完成了人们常说的”目标分解“,同时,”游戏化“也并不需要刻意设计——因为,当你真正面对一个大任务时,画风是这样的:
日程表,你记一下,我作如下部署调整:
以第四任务群,十一任务群加十五、十六两个独立侦查组,强化下周作业的ddl防线; 二、三、七、八、九五个任务群,加六任务群十七突击组,集中力量完成笔记; 十突击群加一个突击组,在托福,GRE一线,阻击到复习时间的单词; 十二任务群配合十二个独立单元,围剿此前找到的知识漏洞; 五任务群和第六任务群的两个侦查组,查找资料; 十四任务群作总预备队,不动!

一些题外话:
在实际中,只用一个简单的预约信号还是过于脆弱,因为有时15min到了,我可能在厕所/室外,开始任务并不现实。所以,我会设计两个启动信号作为缓冲:
- 预约启动信号:信号是打一次响指,一旦触发,14min30s内必须执行”即时启动信号“(保留缓冲,预防真的用完15min);
- 即时启动信号:信号是打三次响指,一旦触发,必须根据现有条件【尽快】开始任务。
此外,这种“神圣座位+下必为例+线性时延”组合而成的策略,还可以轻松地推广到生活的任何方面:
- 比如,为了启动跑步运动,你可以用特定手势作为预约信号,做n下动作,就意味着必须跑步5×n分钟;
- 为了解决ADHD人群常见的洗澡、出门拖延问题,你也可以专门设置对应的洗澡预约信号,出门预约信号;
甚至推广开来,你几乎可以用简单的手势或动作直接“遥控”自己的日常生活——以一种极其轻松、优雅的方式,彻底根除拖延症问题。
12
到这里为止,第一代的自控技术的内容已经完整地呈现出来了。
回头来看,这套技术无论从原理设计、实操落地,还是方法的精巧程度,都已经远远超越了市面上那些流于表面的激励口号、to-do清单或者游戏化设计。
果然,在CTDP诞生后的几年时间里,它在我自己身上爆发出了惊人的效果。
必须坦白地讲,我本人的自制力基础实在是非常糟糕:从小学到高中日夜沉迷游戏,长年饱受ADHD困扰,学习习惯和生活秩序都一塌糊涂,从小到大那是一节课都听不进去,最后侥幸考了个985大学。到了大学初期,环境放松后,甚至在考试周都能吊儿郎当地复习不下去。前面举的DDL越近反而越学不下去的例子,就是曾经真实的自己,可谓自制力基础的地板了。
但自从CTDP诞生后,我一生中第一次实现了长达数周甚至数月的持续自律。借助这个技术,我可以极其轻松地启动任务,并毫无负担地维持连续一整天的高度专注,ADHD的问题似乎在一夜之间得到了缓解。不仅大学后期成绩显著提升,甚至实现了出国交换、发表论文,顺利攻克了托福和GRE,最终还读下了一个硬核的硕士项目。
尤其是在状态最巅峰的时期(例如准备托福和GRE期间),它更是可以让我连续两个月每天高效动员8-10个小时,十几个任务集群、数百个任务单元都能令行禁止、进退有据、天衣无缝。
甚至后来有一次,我在考试复习期中途感冒了三天,还能冷静计算出它对十五天后考试的影响,并从容地从部署在七天后的总预备队中,调配八九个##任务组填补空缺。
(比如这是某次考前一个多月的计划表,每个单元格代表一个##级任务组)
在如此空前的高效自律面前,我一度乐观地以为,自制力的大厦已然建成,剩下的无非只是修修补补了。
然而,很快我就发现,CTDP并不是在任何时候都管用。具体而言,我观察到一种明显的两极分化现象:
- 在大状态本来就有利于自控时,尤其是有DDL等明确压力和目标的时候,例如考试前的复习期,有大量紧迫任务的时间,CTDP的确能最大化利用这些压力,让自制力和纪律性达到前所未有的高度,几乎可以做到每个小时都如臂指使,游刃有余;
- 然而,当大状态本来就不利于自控时,比如在家的闲散时间、身心疲惫、没有明确任务目标时,我往往连触发预约启动信号的意愿都极度缺乏,哪怕多次强行启动,也会在短短几个#任务后便告崩溃。
因此,在随后的三四年里,我曾无数次尝试对它进行改进与升级。然而,CTDP似乎已经穷尽了“1小时尺度的单个行为”这个微观视角下自控策略的极限。无论如何改造,在几年的时间里它都未能寸进,自控状态始终表现出强烈的阶段性和环境依赖性。
就这样,这个瓶颈困扰了我数年时间。直到五年后,我才终于找到了一个更深刻的视角去解释这一切
——并不在传统的“动力”“奖惩”“约束”上着眼,而是用“尺度”的角度去看待整个系统!
13
在新的视角下,我们生活中的各种行为并非由简单的、孤立的,仅仅由眼前的 $V(\tau)$描绘的单一决策节点所组成。实际上,它更像是一棵由无数个连续的、交织的决策节点组成的“行为树”。
这棵行为树中,每个节点的走向都高度依赖于它前面节点的选择;而它在各个时间尺度的宏观走向,又被生活中的各种大大小小的尺度因素高度决定。而其中绝大多数节点,恰恰不适合我们有限的自由意志,或由自由意志驱动的自控策略去介入。
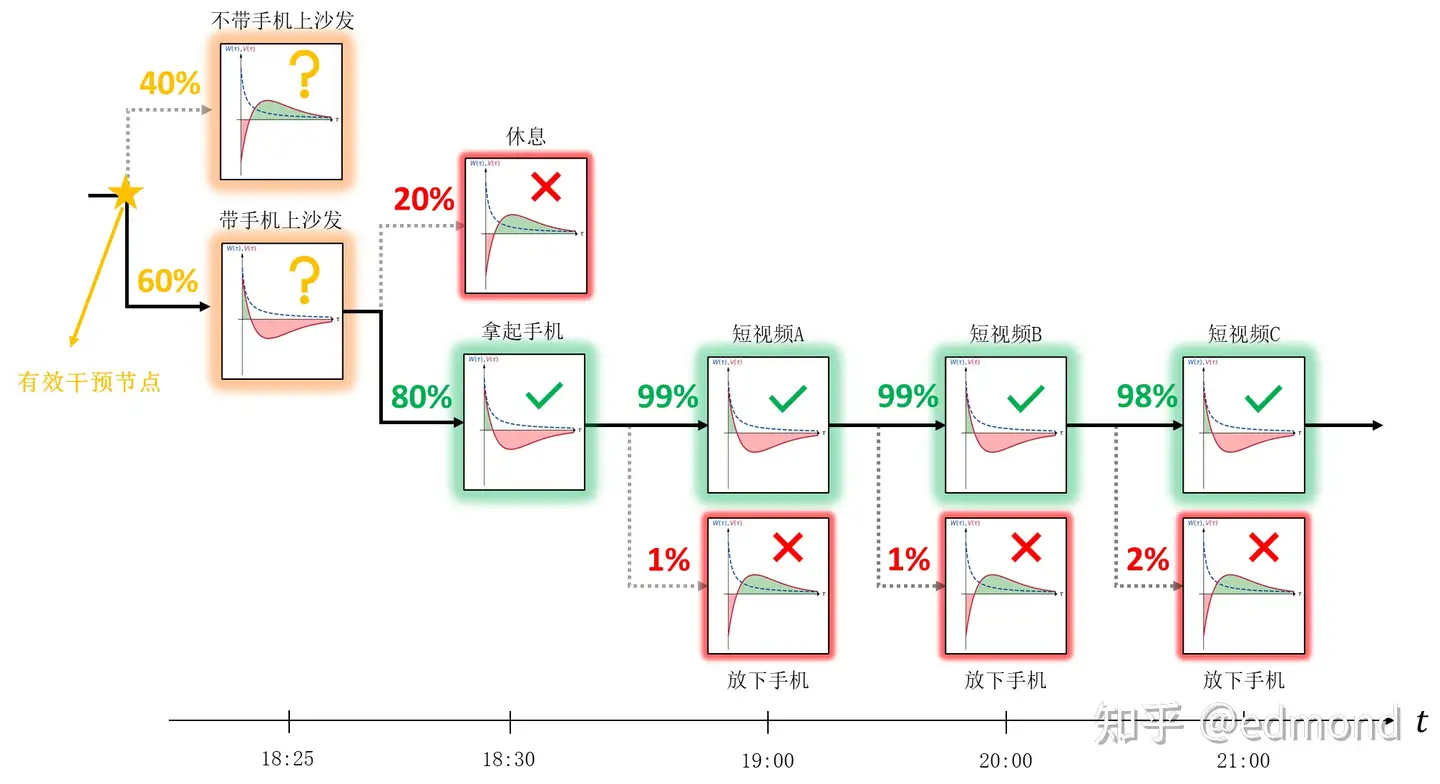
让我们回想一下最开始那个手机陷阱的例子:
某一天晚饭后,你抱着“就刷一小会儿”的心态躺在沙发上,随手打开了短视频App:
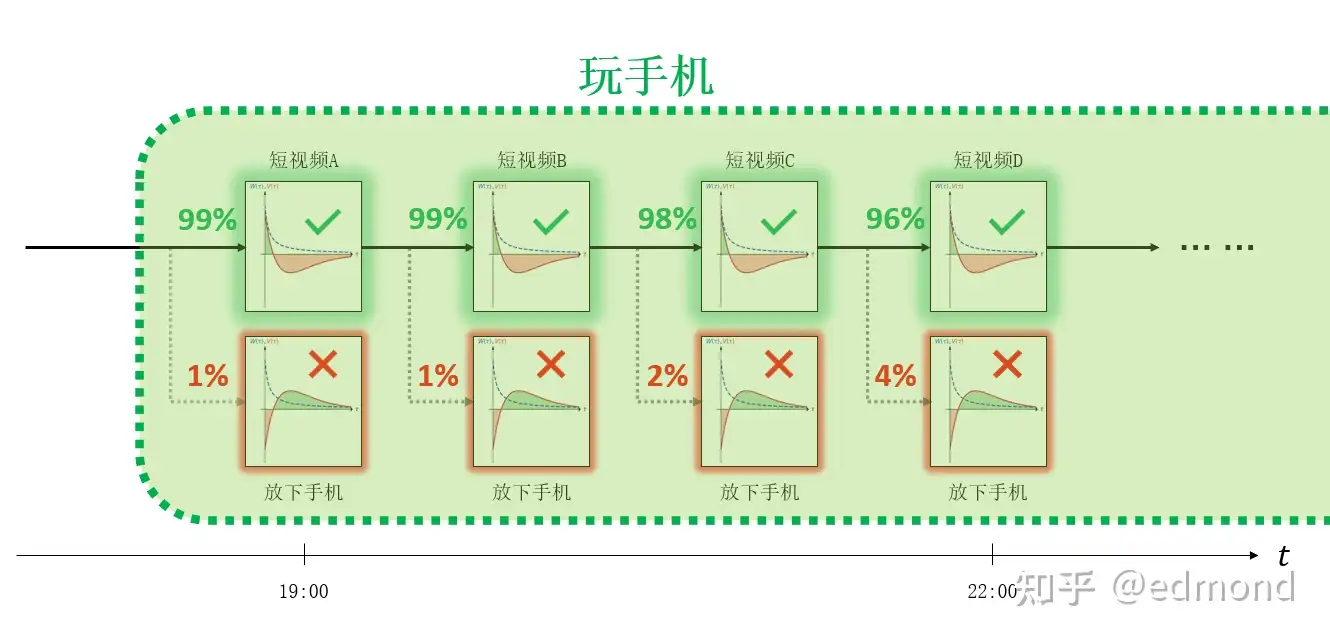
正如前面分析的那样,每刷完一个视频,你都再次面临”刷下一个视频“和”放下手机“的微观选择。但遗憾的是, 短视频放下手机$I(短视频)\gg I(放下手机)$ 的关系对每个微观节点都成立,于是你也就在每个节点都放不下手机。
假如根据你所有过往的选择纪录,统计你最终走向两个分支的概率,你会发现两者的差距极为悬殊——或许高达99%比1%(此处只是概念性举例,并不需要实际统计)。
现在,我们可以引入一个关键的假设——“有限自由意志”假设:
自由意志是存在的,但也是有限的。选项之间的倾向差距越小,自由意志能够有效干预的概率就越高。如果是60%:40%的差距,自由意志尚可干预;但当选项之间的差距过大,比如达到 99%:1% 的程度,自由意志就几乎无能为力了。
实际上,在你躺上沙发、打开短视频App的那一瞬间,你的行为状态就如同被导弹雷达锁定的战斗机一样,陷入了一个难以逃脱的“不可逃逸区”。在这个区域内,你无法仅凭自由意志的微小挣扎从内部挣脱出来,在统计意义上只能坐以待毙。
直到晚睡的焦虑慢慢增长,刷手机的麻木慢慢滋生,两种选项的倾向差距慢慢缩小到自由意志能够干涉的范围时,你才能成功改出这个状态。
换句话说,当你选择拿起手机、躺到沙发上的那一刻,实际上已经在更大尺度的意义上决定了接下来数个小时的虚度。
基于以上观察,我们还可以提出一个进一步的定义:
当一串决策节点的概率差距超过某个阈值(比如90% : 10%)时,我们便可以认定它超出自由意志的干预范围。然后,直接将概率较低的选项忽略不计,把这些微观节点近似粗粒化为一个整体的“不可逃逸区”。
如果从更大尺度上俯瞰,在这些“不可逃逸区”内部,那些看似独立的决策节点,已经被更大尺度的因素(如眼前诱惑、当下情绪、身体的疲惫以及根深蒂固的习惯等)在统计意义上决定。而小尺度的,自由意志的选择,例如刷视频还是玩游戏,具体刷哪一个短视频,反而变得不重要了。
14
这种在不同尺度下,各个影响因素的重要性此消彼长的现象,并不只限于自控领域,而是广泛存在于各种复杂系统之中。
在统计物理学中,有一个优雅而深刻的理论,称作“重整化群理论(Renormalization Group Theory)”,描述的就是这种现象。1966年,美国物理学家利奥·卡达诺夫(Leo Kadanoff)提出了这样一个思想:
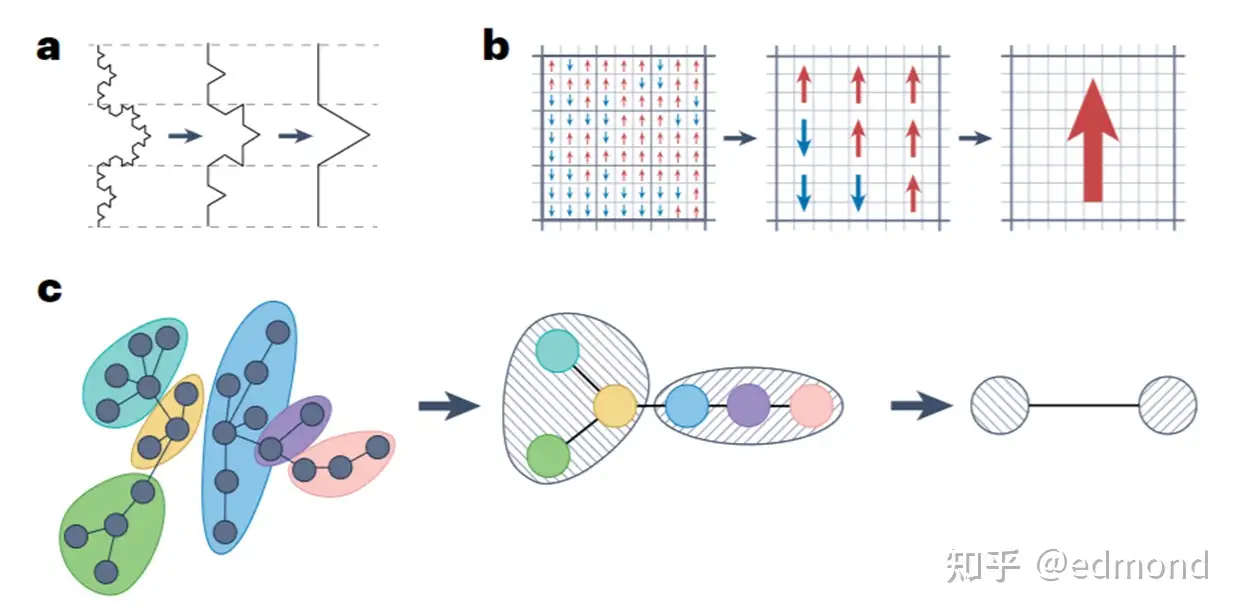
当你改变观察的尺度时,系统内部的自由度会不断被合并(粗粒化),系统的宏观行为会逐渐被少数关键变量所主导,而大量微观变量则逐渐变得不再重要。
为了简单理解这种方法,不妨想象这样一个小游戏:
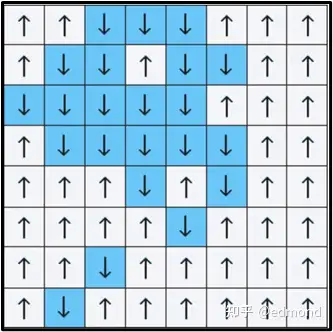
图来源:Olena Shmahalo/Quanta Magazine
你面前有一个很大的格子棋盘,每个格子上都有一个箭头,方向要么向上(↑),要么向下(↓)。我们可以设计一些规则来影响箭头的朝向,比如:
- 可以加入一个规则,让每个箭头倾向于和邻居保持一致;
- 或者反过来,让箭头倾向于与邻居相反;
- 还可以添加局部的噪音、扰动;
- 再比如,有时还可以整体施加外界干预;
在这种密集交错的局部规则下,很多微小的扰动,哪怕一个格子的微小变化都有可能扩散到周围,形成复杂的连锁反应。你可能会以为,要分析出整体的规律,得把每一个箭头都统计清楚才行。
但卡达诺夫说:不必如此复杂。只要我们愿意“模糊”一点,看得粗一点,规律就会自动浮现出来。
他设计了一个聪明的“粗粒化”游戏规则:
- 把相邻的 2×2 小格子合并成一个大格子;
- 用“赢者通吃”的方式,决定这个大格子的方向(比如三个↑一个↓,那整个块就记作↑,如果数量相同,就随机选一个方向,或者按照某种简单规则处理);
- 接着,用新得到的大格子继续重复这个合并操作……
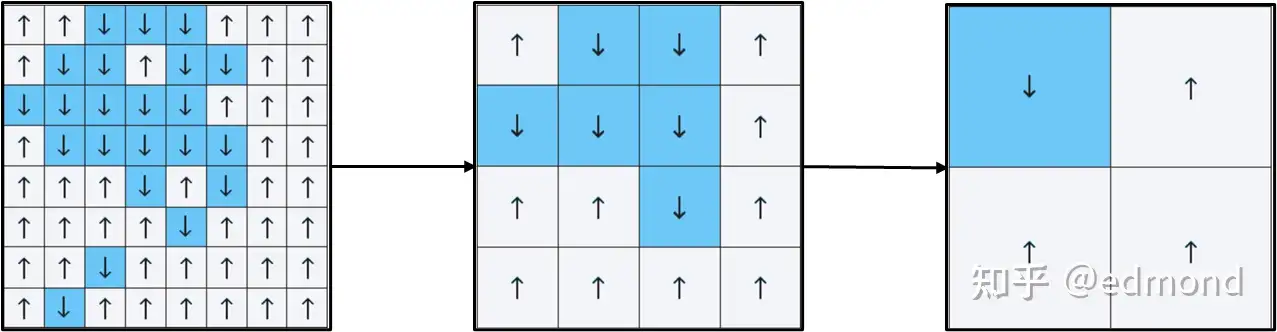
图来源:Olena Shmahalo/Quanta Magazine
经过一轮轮“合并”的粗粒化后,我们的视角越拉越远,越来越模糊。最开始看起来细节纷乱的箭头图,最后只剩下几个大区域,也许大部分方向都趋于一致了。
在这个过程中发生了什么呢?
- 首先,那些作用范围小,各自为政的局部规则,会在合并时被淹没,或自相平均掉,最终在大尺度上完全消失。那些因此产生的结构因此逐渐式微;
- 相反,那些范围更广、一致性更强的趋势,反而能在每一层粗粒化中幸存下来,逐渐在更大尺度上凸显;
- 于是,这种粗粒化不仅会改变格子,还可以改变“规则”本身的强度!一个规则是否重要,取决于你在哪个尺度上看它。在微观尺度上举足轻重的因素,在大尺度中可能毫无痕迹;而那些看起来微弱但一致的趋势,反而可能成为系统最终的主宰力量。
让我们考虑一个简单的例子。
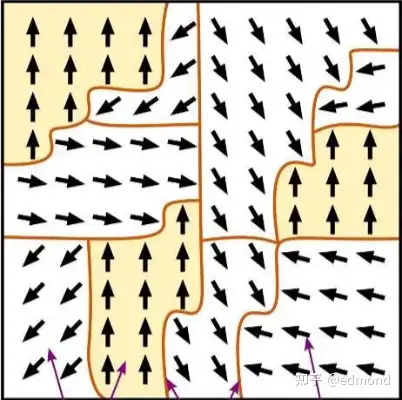
假如,在这个棋盘上,有两种力量在互相角力:
- 一种是短程的交换相互作用,非常强烈,但仅影响最近邻格子,使相邻箭头趋于一致;
- 另一种是长程的偶极相互作用,相对较弱,但可以作用于更远距离,试图让区域的箭头朝向相反。
(注:现实世界中还可能存在各向异性能,热涨落,缺陷,应力等复杂因素,这只是一个非常简化的启发式讨论)
Heutling, B., Uebrig, A., & Awerbuch, M. (2023). Wirbelstromprüfung von ferritisch-austenitischen Duplexwerkstoffen und Nickel mit Phasenauswertung in der Wärmetauscherrohrprüfung. DGZfP Jahrestagung 2023, Friedrichshafen, May, Germany
在没有外界干预的情况下,这两种力量之间开始了一场拉锯战:
- 交换相互作用倾向于让局部格子全都拉成一个方向,形成大量局部同向的小区域;
- 偶极相互作用又不允许整个系统朝同一个方向太久,它试图从远处“拉扯”这些区域,促使它们之间方向交替,形成相互抵消的排列;
最终,在这两股力量的竞争与妥协下,达成了一种精妙的平衡:你会看到,大片的箭头自动聚集,形成了一块块大小不一、方向交错的“岛屿”。每个岛屿内部方向统一,而不同岛屿之间则方向各异。这些岛屿相互镶嵌,最终稳定成了一种复杂而稳定的“拼图”结构。
在现实世界中,这种现象被称为“磁畴”(Magnetic domains),它正是经典的短程交换-长程偶极竞争模型的结果。
15
那么,当我们在不同的尺度下观察这个棋盘,情况又会如何呢?
- 在微观尺度下,我们主要看到一片片方向高度统一的局部区域: 此时交换相互作用非常强大,迅速让周围的格子方向趋于一致;而偶极作用由于太弱,在这个微观视角下几乎不可察觉。
- 但当我们粗粒化到更大的尺度后,我们看到的却是不同方向相互交替的大型区块: 此时虽然交换作用虽强,但作用范围过短,只能影响内部小尺度的统一趋势,话语权不会随粗粒化而增长;相反,偶极相互作用距离足够远,在大尺度下,它微弱的作用不断叠加、缓慢积累,逐渐占据主导地位,形成了明显的宏观结构。
这种现象,就是重整化群思想所揭示的最深刻的一点。
一个因素的重要性,往往取决于你所处的观察尺度——在小尺度中举足轻重的规则,在更大尺度下可能完全被平均掉;而那些在小尺度几乎不可察觉的长程趋势,却可能在粗粒化的过程中层层累积,最终主宰系统的宏观走向。
重整化群思想在不同研究对象中的应用。图来源:Klemm K. A zoom lens for networks[J]. Nature Physics, 2023, 19(3): 318-319.
这就是整个物理世界最普遍的规律之一:
- 一杯水在微观上是无数分子复杂而无序的碰撞,在宏观上却只用温度、压力和体积几个简单变量就能完整描述;
- 一根磁铁在原子尺度下磁矩杂乱无章,在宏观尺度下却凝聚出明确的南北磁极;
- 一根弹簧的每个原子都服从复杂的量子力学,但从外面看,宏观上却只是一个简单的胡克定律 $F=kx$ 。
- 在金融市场中,小周期的走势无论怎么复杂折腾,最终都会服从大周期趋势定下的剧本。
随着观察尺度的不断拉大,大部分局部的涨落,短程的波动,微观的规则,会自动被合并,被抵消,被吸收进其他变量中。而系统最终的宏观行为,只取决于极少数范围广,一致性强,能在更大尺度上不断积累存活下来的变量。
(注:这两节仅作对生活启发式的比喻,绝非严谨的推理)
16
可怕的是,像这样的重整化思想,其实可以推广到整个生活本身。
回顾一下前面设定的规则:当选项间的统计概率差距超过某个阈值(比如90%)时,我们便认为自由意志不可干预,将其视为为一个“不可逃逸区”——你会发现,我们的生活绝大多数的时间,就是由大大小小的“不可逃逸区”,像磁畴一样拼接而成的。
当你深夜躺在床上刷短视频时,就是一个负面的“不可逃逸区”,你大概率不会在中途突然放下手机;
你吃饭的时候,还是一个不可逃逸区,你大概率不会吃着突然停下来去图书馆学习;
你学习的时候,则是一个良性的不可逃逸区,你进入状态后,不遇到阻力也不会轻易停下。
或许你会说:“等等,我们似乎总有一些时刻还有选择的余地吧?”
但很遗憾,拉到更大的尺度来看,那些表面上的自由,又笼罩在更大的“不可逃逸区”下:
- 你昨天晚上只睡了三个小时,你的剧本大概率是一整天废了,哪怕选择开始学习也难以坚持,会收敛到一边疲劳一边刷手机,靠手机的高刺激来维持清醒的“不可逃逸区”;
- 如果最近几天你完全没有任何DDL、窝在家里无所事事,那么大概率你会陷入持续性的“手机与游戏交替”的循环状态,这同样是一个宏观尺度的“不可逃逸区”;
- 随着期末考试的ddl临头,你这个月的剧本往往是一开始颓废拖延,到考前几天又能轻而易举地进入学习状态,最后悔恨为啥不早点开始;
我的朋友,像俄罗斯套娃一般层层嵌套的剧本、循环和不可逃逸区,就是我们生活的真相。
我们的一分钟有几种过法?或许有成百上千种:你可能在刷短视频A,也可能在刷短视频B,可能在读书,也可能在做某一道题。
但如果把时间尺度稍稍拉大一点,我们的一小时可能只有几十种过法;可能就是刷短视频/学习/通勤/吃饭;
到了一天,可能只有十几种过法;一个月,或许只有七八种典型的模式;拉到一年的尺度来看,你可能会惊讶地发现,我们的一年竟然只剩下三四种大致的剧本了。
随着视角拉远,我们将整个事件链逐级粗粒化后,那些小尺度细节的影响越来越小,被逐步平均掉,整个系统越来越被那些对应的大尺度因素所左右,比如环境、工作、习惯、性格等等。小尺度的变量控制着小尺度的剧本,大尺度的变量控制着大尺度的剧本:
- 你的注意力状态控制着你每一秒钟的思绪;
- 当下正在进行的事情牵引着你每一分钟的注意力;
- 今天的日程安排决定了你每一小时具体在做的事;
- 最近几天的精力和情绪状态,影响着每天的具体安排;
- 再往上,你的作息规律、情绪周期和环境条件,控制着你近期的整体生活状态;
- 而你的身份、性格和社会处境,则决定了你长期的节奏,最终塑造了你整个人生的模样。
在每个特定的尺度上,相应的因素一旦给定,它们就会成为一种稳固的“边界条件”,让系统在当前尺度内自发地形成若干个明确而稳定的“稳态”。
往下,每种稳态都由若干个更小尺度的稳态排列组合而成;向上,若干个这样的稳态又进一步组合起来,形成更大的稳态结构。
这些稳态高度稳定、高度重复,并且高度取决于对应尺度的那些关键因素。正是这些大大小小的影响因素和稳态,交织在一起,共同构成了我们日常生活的“生态环境”。
这么看来,处于最底层的“自由意志”,真是人生中最大的错觉。
我们每一秒都完全地拥有自由意志,每一分钟都看似拥有自由意志,每一小时都比较拥有自由意志,而到了每一天,每个星期,似乎又不怎么拥有自由意志了。在宏观上,我们只是一片在环境,习惯,境遇,性格,利害关系组成的汪洋大海中身不由己,随波逐流的浮萍。
而人类一切自控策略的本质,其实又是用最小尺度的自由意志,在各种规则的支持下,去自下而上地克服大尺度不利因素,撬动更大尺度行为的尝试,这无疑是难如登天的。
所有的努力、口号也好,CTDP也罢,都只不过是试图在这片汪洋大海中掀起苍白而无力的一朵浪花罢了。这就是自制力薄弱的我们,天然会遇到的悲剧。
17
现在,我们终于可以回过头来,更清晰地看懂CTDP作为一个典型的局部行为干预策略,究竟遇到了哪些瓶颈。
第一个瓶颈,是“尺度受限问题”:CTDP天然只能影响局部行为,无法撬动这些行为背后的长期因素。
CTDP的核心原理,是通过一系列精妙机制,在短期(比如一小时的专注任务)内放大理性倾向、降低启动阻力,从而极大地提高单次行为的执行力。在微观尺度下,它的确展现出了惊人的有效性。
但问题在于:我们的生活并不是一连串孤立的小时拼凑而成的。“此刻不愿意启动任务”只是表面现象,而造成这种“不愿启动”的更大尺度因素,比如精力状态、情绪波动、明确的目标感、生活节奏甚至长期习惯,才是真正的本质。
当这些大尺度因素对你不利时,即便用再精妙的策略去强迫自己当下学习一小时,其效果也往往非常有限:
- 如果你最近熬夜频繁、身心疲惫,你连理智上都不会想学习下去,而CTDP无法解决熬夜本身的问题;
- 如果你近期完全没有明确的任务、也没有迫切的DDL,那么CTDP同样无法督促你去主动自学,毕竟你从来没有自学的习惯。
因此,CTDP的第一个致命局限,就在于它只能影响微观的节点,却无法向上撼动那些决定我们生活基调的宏观因素——它无法让你精力充沛,也不能让你心态平稳,更不可能动摇你的习惯或生活模式。
第二个瓶颈,是“稳态回落问题”:即便我们短暂改变了生活状态,系统也会自发回落到原有的稳定模式中。
当更大尺度上的精力状态、生活节奏、心态、习惯等因素被确定后,系统便会自然形成一系列高度稳定的行为模式。比如说,假期刚开始回家时,“打游戏”和“刷视频”可能就是最容易维持的生活模式,于是你的日常大概率会在“打游戏”和“刷视频”之间循环往复。
CTDP的问题就在于,它只能临时地干涉系统的某些节点,即便强行将某几个小时的替换成高效的学习模式,但这又怎么样呢?
系统的稳态,依旧是原来的那套稳态!把时间尺度拉长,这几个小时的高效,还是会淹没在大片的打游戏和刷视频中。
对于那些被习惯、作息、情绪状态决定的更大尺度(日级、周级)的稳态而言,这几个小时的高效甚至掀不起一朵浪花,更别说对稳态本身有什么改变了。
这种自发回落的机制,正是“反弹”、“恢复原状”、“间歇高效”现象频繁发生的根本原因。
第三个瓶颈,也是最为根本和绝望的,是“约束力耗散问题”:任何偏离稳态的尝试,都是在消耗资源(比如意志力)去维持一个亚稳态,而这必然无法长久。
当一个人的行为系统在大尺度上形成了某种稳定结构后,它就像一个自洽的生态系统,具备天然的“稳态吸引力”。任何想要摆脱这个稳态的努力,本质上都意味着需要持续投入各种资源:
- 或许是你珍贵的意志力;
- 或许是CTDP所精妙设计的沉没成本;
- 或许是各种各样约束规则,打卡,监督;
但问题在于:这些资源是有限的。当你试图维持一个偏离原有稳态的“亚稳态”时,哪怕开始阶段非常成功,也会在持续的负面因素中磨损殆尽,最终约束崩溃,回落到原有的样子。就算激进地一次性改变整个状态,其所需要的资源和力量又让人难以维持。
有没有可能存在一个高于当前稳态的,“下一个更好的稳态”呢?
确实有可能。有时,即便在大尺度因素不利的情况下,你也可能偶然连续高效几天。但遗憾的是,这种状态往往可遇而不可求,过不了多久,你的生活又会回到原本的样子。
最可悲的是:几乎所有自控手段,都不具备长期地,整体地,一蹴而就地改变整个稳态的力量。
这些自控手段,都只是在用有限的资源,去支撑那点局部的约束规则,却无力整体迁移。当迁移失败时,这些策略就陷入“按下葫芦浮起瓢”的困境:这边约束住了学习,另一边生活秩序乱掉了;这边规律作息了,那边情绪状态又崩溃了。
这是因为,一个大型的负面稳态往往是多个小的负面稳态交叉而成:晚睡导致毫无精神,无精打采时更容易沉迷游戏,沉迷游戏让你追逐刺激,追逐刺激让你更加晚睡。这种综合性的负面状态,犹如常山之蛇,击其首则尾至,击其尾则首至,击其中则首尾俱至。
最终,你不得不承认一个残酷的现实:
在资源有限的前提下,所有试图脱离当前基态的努力,几乎都面临同一个命运——短暂成功后迅速回落,无法实现真正意义上的稳态跃迁。
总而言之,这三个瓶颈共同构成了CTDP难以逾越的理论极限。想要从根本上突破这些局限,我们势必需要一种全新的、更具全局视角的第二代方法。
而在数年之后,我才找到了真正能解决这些问题的钥匙。
18
那是一个雨夜,当时我申博刚拿到offer,却又被签证问题卡住,百无聊赖之下点开了一个象棋解说视频。说的是1960年四川棋手访问武汉的表演赛上,李义庭对陈德元的那盘“单马擒王”名局。
讲到最后,解说提到:
行棋至此,红棋已经形成了“三步杀”的局面。
所谓的“三步杀”是什么意思呢?
意思是,进入了这个局面之后,黑棋其实已经必死无疑,无论它如何应对,红棋总能在三轮之内将黑棋杀死。黑棋所有的挣扎,都只能延缓一下自己被将死的时间,甚至如果挣扎不当,还可能让这个时间提前到来。
那么,黑棋为什么会落到这般田地呢?
当然是因为它的上一步棋走错了。如果黑棋能够悔棋,退回到上一步,或许就能避免陷入“三步杀”的死局;如果回溯到上一步时仍然是“四步杀”,仍然无法避免被杀死,那说明上上步棋就已经走错了。以此类推。
你会发现,倘若一直回溯,必然可以回溯到某一步,使得黑棋获胜的希望重新出现!(至少在计算机搜索范围内,红棋找不到必胜法)。
而这一点,恰恰是第二代方法的破局关键。
回到一开始躺在沙发上玩手机的例子。
当躺在沙发上刷视频时,其实我们已经不可避免地进入死循环了,但是,如果我们往前回溯呢?
- 为了避免开始刷视频(99%:1%:),我们就得避免在沙发上拿着手机(80%:20%);
- 为了避免在沙发上拿着手机,我们就得避免把手机带上沙发(60%:40%);
- 还可以继续,为了避免带手机上沙发,我们就得避免进入容易带手机上沙发的状态(50%:50%)……
——往往在这一系列事件的回溯过程中,你越是回溯到更早的节点,两个选项之间的倾向差距就变得越小!
于是,我们终于发现了一个令人振奋的规律:
对任何一个看似无法逃脱的“不可逃逸区”,我们都必然可以回溯到某一个节点——在这个节点上,两个选项之间的倾向差距足够小,进入了自由意志的有效干预范围,让我们有能力真正避免进入最终那个负面的死局。
也就是说,每一个看似强大的,大尺度的负面稳态,都可以映射到一个弱小的,小尺度的有效干预节点上!
而这个节点,才是“不可逃逸区”的真正边界所在。
19
有趣的事情来了:
正如前面所述,我们生活中所面临的负面状态的种类,其实是极其有限,且高度重复的;而对任意一种负面状态,我们又总能通过回溯,将其映射为一个有效的干预节点。
那么,倘若我们对它精准地施加约束,就可以实现“四两拨千斤”的效果,防患于未然,从一开始就避免进入那些负面状态。这个约束,就是这个局面的局部最优解。
更让人欣喜的是:既然负面状态本身是可重复的,那么针对这些状态的“局部最优解”自然也同样是可重复的!
举几个例子:
- “从一开始就不带手机进卧室”比“带手机进卧室后,忍着不刷手机”容易许多倍,那么从一开始就不带手机进卧室,自然就是解决“睡前刷手机”问题的最优解;
- “进家门后无事可做时马上洗澡”比“已经躺在沙发上玩手机时,强行爬起来洗澡”容易许多倍,那么规定进家门15分钟内必须开始洗澡,就是解决“洗澡拖延”问题的最优解;
(这个规定的约束力从何而来,在后面会讲解)
在象棋、围棋等棋类游戏中,这样针对某种特定局面、可重复应用的最优操作方案,被称为“定式”。
所谓的定式,其实是无数前人经过深入研究后总结出的局部最优解:在特定局部局面下,黑白双方棋手都必须严格按照定式行棋;任何一方一旦脱谱,就会不可避免地留下破绽。
即便在千变万化的棋局中,棋手们通过熟练掌握一个个局部定式,也能够极大地提升自己的整体棋力。
而我们,也恰恰可以像棋手学习定式一样,用“分治算法”的逻辑来逐个破解生活中的负面状态:
- 首先,我们可以识别出生活中的典型负面问题;
- 每个负面问题又可以进一步拆解为若干个负面的稳态;
- 而每个负面的稳态又都能通过回溯映射到对应的有效干预节点;
- 最后,每个干预节点,我们都可以为其量身定制一个精准的“定式”去破解。
如此一来,我们便能将有限的自控资源,精准地集中在那些真正最关键的节点上,对那些高度重复的负面状态,一个个进行降尺度打击了。
如果四两可以拨千斤,那么何妨用八两去拨两千斤,用十二两拨三千斤,用十六两去拨四千斤?
20
更妙的是,八两拨动的,可能还不止两千斤。
假设我们真的找到了一个局部定式,并愿意投入一定的资源(比如方法设计、意志力投入或外界约束)去实施,成功地将某种负面状态从生活中彻底“ban”掉了——比如再也不会带着手机躺上沙发,或者每次回家后都能立即去洗澡。
那么,由于它的作用尺度足够长,这个“定式”本身,也会加入到影响我们生活稳态的众多大尺度因素中,成为其中的一员!
此时的稳态,还是原来的那个稳态吗?
显然不是了。如果把最初的稳态记作$E_0$ ,那么,当第一个定式被成功引入后,你的生活会逐渐进入一个稍有改善的亚稳态 $E_1$。在新的稳态$E_1$中,由于状态整体上变好了那么一点点,你再引入第二个定式的难度便会降低一些。同理,第二个定式加入后,你又进入了更优化的亚稳态 $E_2$ ,在$E_2$ 中引入第三个定式又会变得更加容易。
举个例子,你如果从此“不在沙发上玩手机”,实行“回家后马上洗澡”也会稍微容易些;如果每天回家后马上洗澡得到了清爽的状态,实行“在睡前不刷手机”也会因为解决了洗澡拖延症,而容易了一丢丢。
每引入一个新的定式,都可能产生“1+1>2”的效果,最终以一种类似“切香肠”的方式,渐进地改良你的生活,一步步向更好的长期稳态跃迁。
正如《孙子兵法》所言:“善战者,胜于易胜者也。”
解决了简单的问题,原本中等难度的问题就变成了简单的问题;如果我们又攻克了这个新的简单问题,那么原本困难的问题,也变成了简单问题。
我们从头到尾,解决的都是简单的问题。
好了,我们已经找到了一系列定式,每个定式都能从一开始就避免进入一个负面的“不可逃逸区”。但若想彻底实现大尺度上的稳态迁移,我们最终还是不得不面对那个最根本的挑战——约束力局限问题。
正如前文所分析的,所有的自控策略,本质上都是在用有限的资源去支撑某种局部的约束规则。这就不可避免地导致了“按下葫芦浮起瓢”的困境:刚刚从$E_0$到$E_1$,$E_1$到$E_2$说得倒是挺美,但实际上可能发生的是,你根本没有这么多精力去维护这些定式。
- 当你试图加入一个新定式时,原来的某个旧定式可能突然崩溃;
- 或者你揠苗助长,一开始就强行上马一个要求过高的定式,还没等它改善整体状态,维护它就耗尽了所有的资源;
- 再或者你引入了一个与现有定式不兼容的新定式,结果导致整个系统瞬间崩盘。
换句话说,引入定式的顺序本身也至关重要,并非任何随意的顺序都能支持你抵达下一个稳态。此外,这么多定式的约束力从哪里提供?
为了彻底解决这一难题,我们还需要引入一个新的巧妙算法——“递归回溯算法”。
21
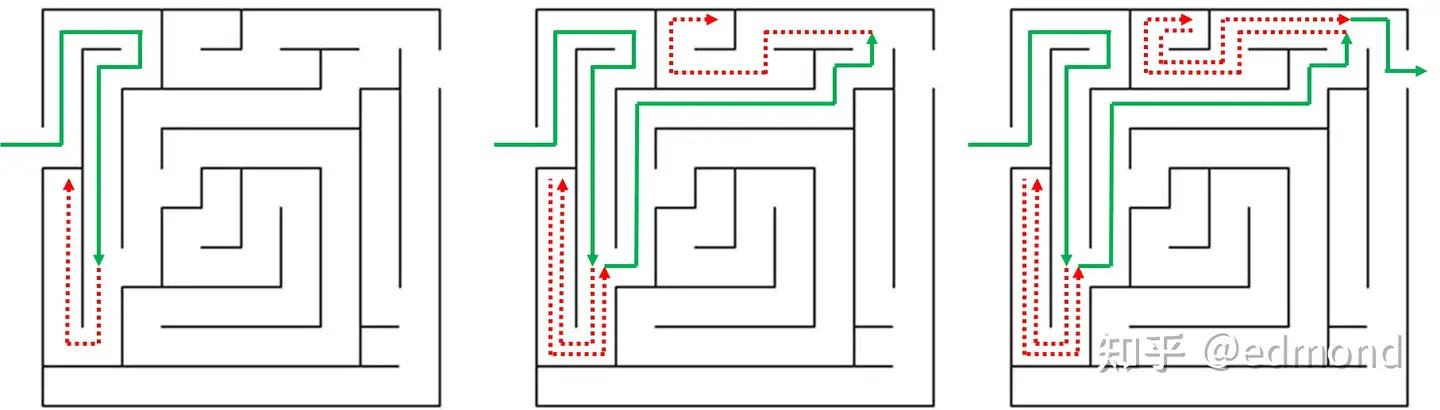
所谓的递归回溯算法(Recursive Backtracking Algorithm),其实是一种在计算机科学中广泛使用的经典算法思想, 它通常被用来解决这样的问题:当你面对一个可能性极其庞大的系统(例如走迷宫、下棋)时,如何在有限资源的前提下找到一条可行的、甚至是最优的路径。
最典型的例子就是迷宫问题:
想象你被困在一个迷宫里,你不知道哪条路通向出口,也没有地图。你能做的,就是不断尝试每条可走的路径:
- 每次遇到岔路口,你先随机选择一条路径;
- 如果走下去发现这条路走不通了(死路),就退回上一个路口,尝试另一条可能的路;
- 如果新路也不通,就继续回退,再换方向,直到你最终找到一条通向出口的路径为止。
这就是“递归回溯算法”的核心逻辑:尝试 → 失败 → 撤回 → 换路径 → 继续尝试,直到成功。就像在下棋时,通过不断地悔棋来确保找到一条必胜之路一样。
那么,我们该如何应用递归回溯算法,来设计这些“定式”的添加顺序呢?
假设我们针对生活中的各种负面状态,设计了一系列对应的定式,比如:
- 保证回家一定洗澡的定式 (A);
- 保证不带手机上沙发的定式 (B);
- 保证晚上不刷小红书的定式 (C);
- 保证吃完饭尽快洗碗的定式 (D)
- ……
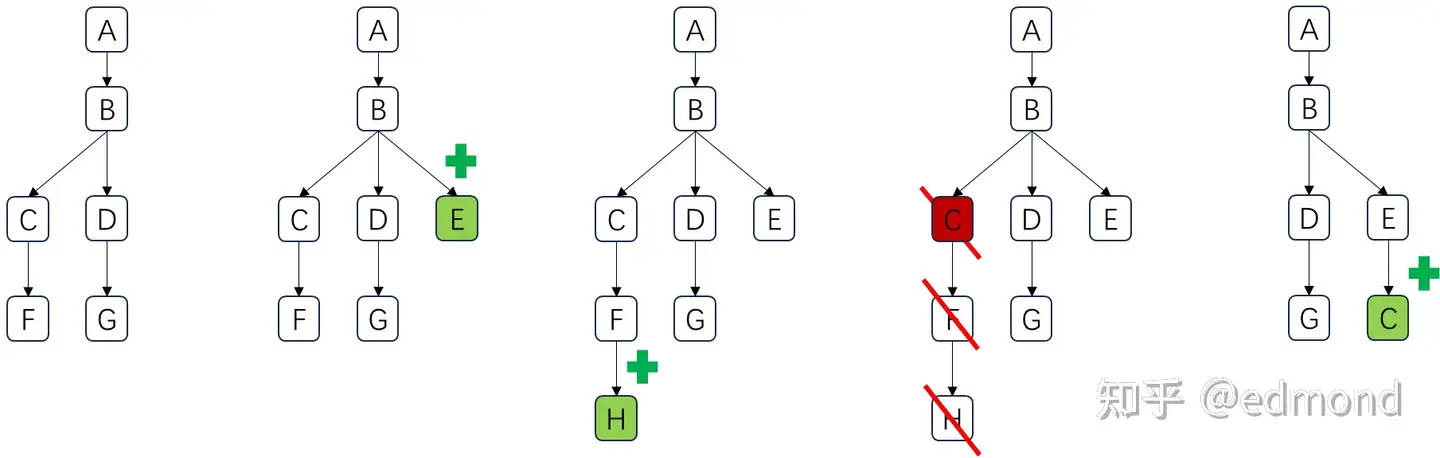
此时,我们就可以用下面这种“定式树”的方式来组织和管理它们:
- 定式的添加规则:每天最多只能将一个新的定式作为子节点加入到定式树中。 例如,我发现H定式和已有的F定式是高度相关的,那么我可以将H定式作为F的子节点加入; 如果发现E定式看起来像是全新的一个领域,我也可以直接建立一个新的分支。
- 定式的删除规则:以“堆栈结构”来管理,一旦删除某个定式,就同时删除它的所有子节点。 例如,定式C有一次执行失败了,这就说明C定式以及后续的F,H组合并不稳定,那就大大方方地将其删除,同时删除其后续的F,H定式。(当然,未来还可以重新尝试将C定式再次加入树的末尾)
表面上RSIP的画风
经过这样反复迭代,我们便自然解决了“定式加入顺序”的搜索问题,以及“约束力来源”的问题!
- 一方面,加入得越“自然”,越容易维持的定式,越容易稳定地留在这棵树的根部。
原因在于:在这样的迭代过程中,如果某个定式的维护成本过高,在当前状态下无法稳定维持,它就会自然崩溃,重新退回到树的末梢;反之,那些加入得轻松、维护得毫无负担、对整体状态改良明显的优质定式,则能更容易被保留在树的根部。
久而久之,这个定式树最靠前的节点,反而全是些看似鸡毛蒜皮、却能带来巨大正面效应的小规则。你猜我现在的一号根节点定式是什么?竟然只是“在家吃完饭后必须尽快洗碗”。虽然听起来不起眼,却能切实避免掉一个更大的颓废状态。
正是这些简单微小的改良堆积在根部,才会让整个定式树的根基越来越稳固,像游戏中的”叠被动“一样,持续为大状态提供微小的改良,支持整棵树步步为营地前进,这才是真正的”胜于易胜“。
- 另一方面,这种堆栈结构也会天然地为新加入的定式提供强大的约束力。
试想一下,既然每引入一个定式都需要一天的努力,那么假如某个拥有四个子节点的定式突然失败了,这就意味着你整整五天的努力、整整五个对自控有效的定式瞬间白费——而这种损失,在你准备放弃的瞬间就会发生。
这便是它的第二个妙处:越靠近根部、子节点越多的定式,损失代价越大,因而被保护得越好。
直到最后,那些深埋于根部的定式,会因为执行时间已经很久,慢慢内化成为你的习惯,维持所需的资源越来越少,最终几乎可以忽略不计了。这时,节约出来的约束力便可以投入到新定式的开发中。
就这样,我们最终实现了自控策略的奇迹——通过将局部最优解集成到定式树中,进行递归回溯探索,累积起来,就能将小尺度的自由意志,放大到足以影响全局的地步。
而从这里开始,你可以真的开始改造作息,培养精力,改善健康,调控生活节奏,戒掉你想戒掉的习惯,养成你想养成的习惯,让这些以前看似不可撼动的大尺度因素,开始为你所用。
而这套方法,就叫做递归稳态迭代协议(Recursive Stabilization Iteration Protocol, RSIP)。
22
当然,在实际应用中,如果想把RSIP游戏化,也轻而易举。
因为,在现实中,这套方法早已有一个几乎一模一样的对应物——那就是著名战略游戏《钢铁雄心》系列里的国策树(National Focus Tree):
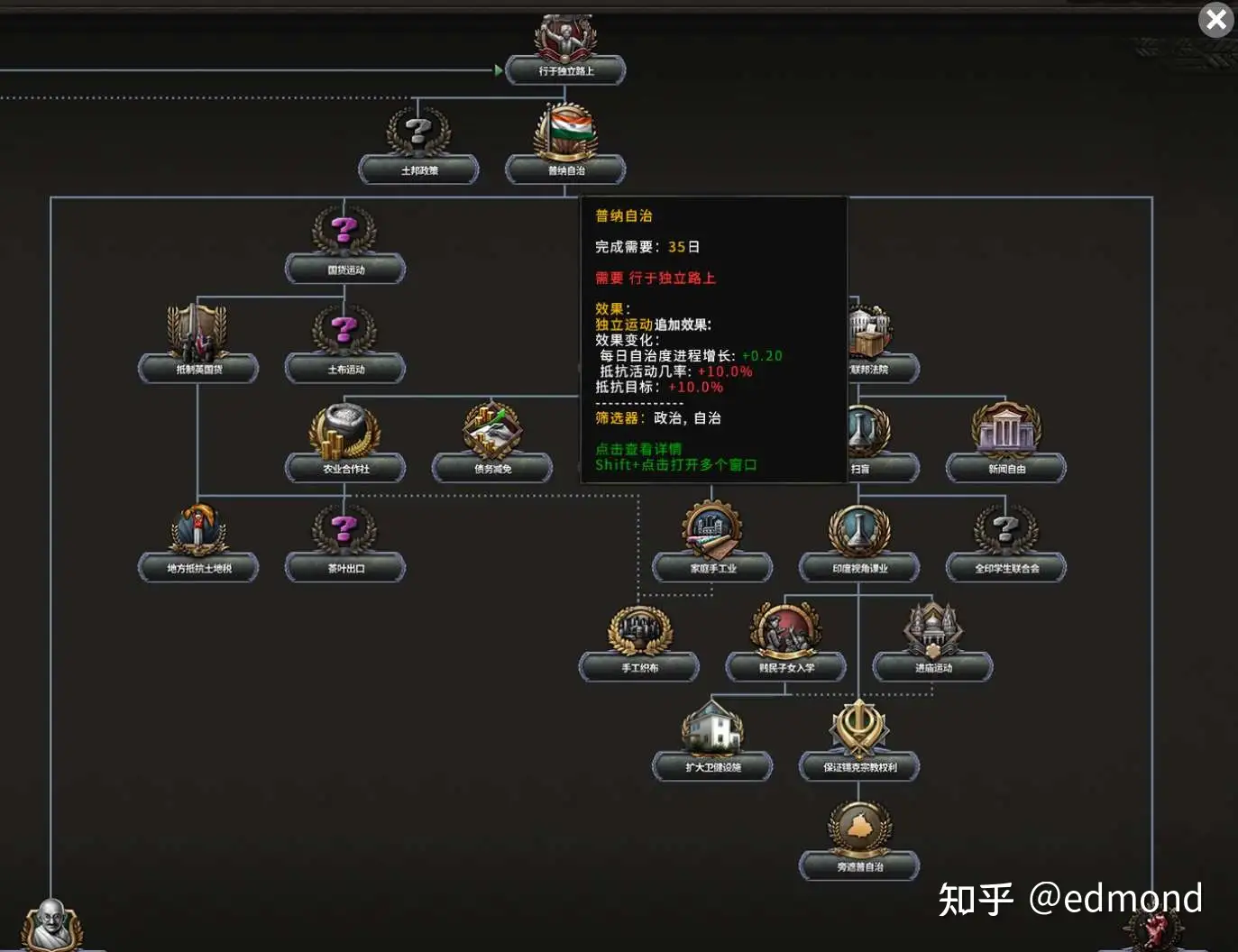
实际上RSIP的画风
在这款游戏中,每个国家都有一棵庞大的“国策树”,树上布满了各种形态各异的国策节点:
- 有的用于工业扩展;
- 有的强化军事建设;
- 有的决定外交走向;
每个国策都能为玩家提供各种各样的增益效果,而选择与设计自己国家的国策树,更是这款游戏的最大魅力之一。
现实应用中,我自己也喜欢用思维导图软件(比如MindMaster)来管理这样的国策树;为RSIP设计各种各样国策的过程,其实也极具趣味:
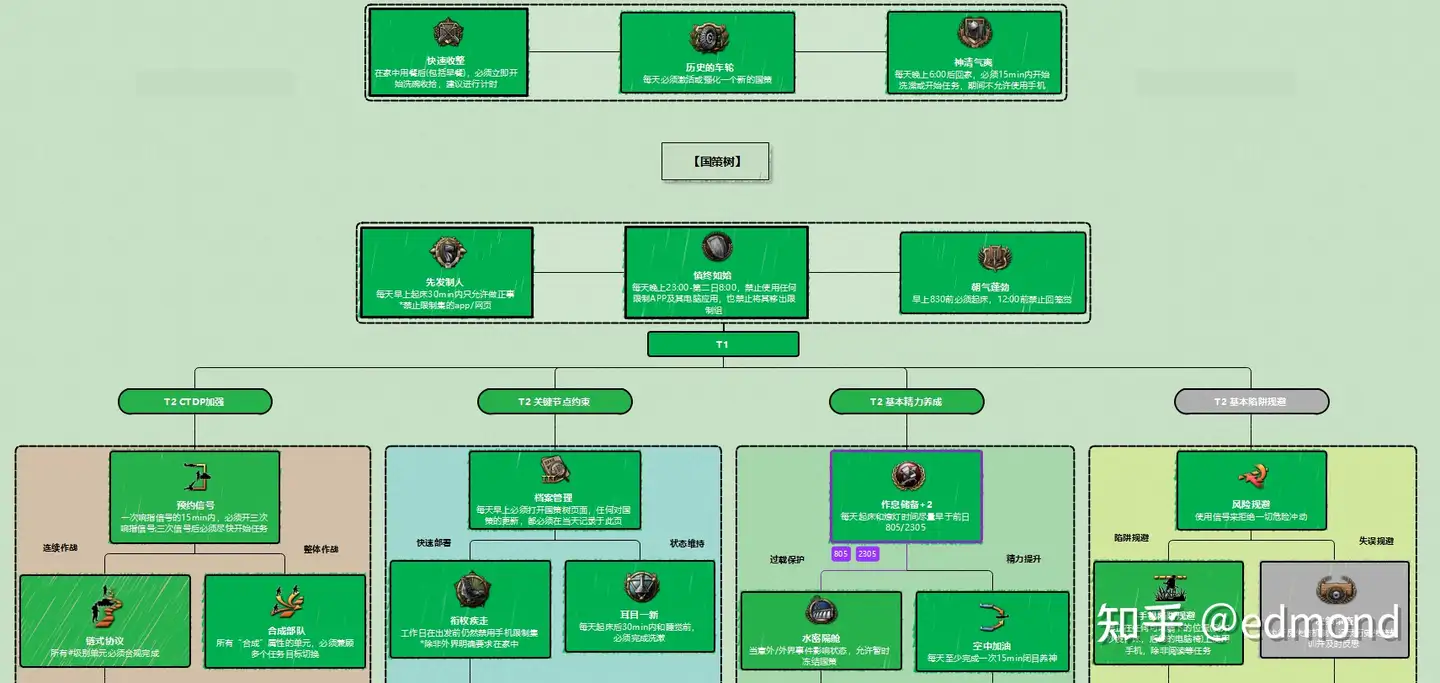
- 比如,针对晚上的洗澡拖延症问题,我设计的“国策”是: 利用苹果手机的自动化功能,一旦晚上定位从外面回到家里,就自动启动15分钟倒计时,必须在倒计时结束前进入浴室开始洗澡;
- 又比如,为了应对早上起床后玩手机,导致全天浑浑噩噩的问题,我设计的“国策”则是: 起床后的前30分钟内严禁使用手机,只能用来做一些正事,比如洗漱、整理、吃早餐或看邮件,从而激活一天的状态;
- 而为了确保RSIP系统本身能够持续稳定运行,我还专门设计了一个位于最根部的“根国策”: 早上起床这段时间,必须打开国策树的思维导图页面,并且,每天必须加入一个新国策。
诸如此类。
事实上,当下网上绝大多数对自制力的讨论,其实都是不成体系,极其零碎的”建议“。但实际上,它们也可以设计成一个个“国策”,吸纳进这个系统中。接下来的应用,诸君还可自由探索。
后记
这篇文章的诞生契机,源于我此前在小红书上偶然看到@Allvinn 的一篇关于ADHD的笔记。当时,只是感触于这些年来自己与ADHD和自控问题苦苦挣扎的经历,随手写了一些评论,没想到却因此萌生了将这些年积累的思考整理成文的想法。
坦白讲,我本人并不是什么特别优秀的人。只是一个非常普通的学生,从小在父母的溺爱和对游戏的沉迷中长大,长期被糟糕的习惯和严重的自控问题所困扰。在过去的人生中,我的成绩也时常在垫底和名列前茅之间反复起伏挣扎。幸运的是,后来一路磕磕绊绊,也读上了研究生和博士,成为了一个平平无奇的科研搬砖工,得以在一方实验台上安安静静做着自己喜欢做的事情。
其实,大多数人自蒙昧时代起,就会或多或少地思考一些与“自律”相关的事情,而我也不过是碰巧将这种思考持续得更久一点而已。
然而,到了文章的结尾,我其实更想传达一个信息:
我极为反感现在许多营销号、知识博主,对“自律”和“方法论”的过度神化和推崇。仿佛只要学会他们的方法论了,参加他们的训练营了,就自律了,努力了,逆天改命了,开始逆袭了。
我并不这么认为。
事实上,自控方法从来不是什么能让人生开挂的灵丹妙药。
即便你实现了绝对的自律,那又能怎样呢?这也仅仅只是你人生无数块拼图中的一块而已,甚至还不见得是其中最重要的一块。
在人生中,比这重要的拼图还有很多——身体和心理的健康,家庭环境,社会资源,个人性格,人际关系,再比如难以捉摸的运气,甚至你所处的时代本身,它们都能像命运的礁石一般,像道尔顿板上的钉子一样,将一个聪颖而自律的年轻人的努力,推向未知的远方。
我们这个时代,确实有不少人苦于缺乏自律;但过度自律,苦于内卷压力和对“优秀”的执念的人也不少。自律从来不是所有人都需要的东西;很多人更需要的,反倒是放松,健康而自由地做自己喜欢的事。
所以,这篇文章的努力,其实只是试图帮助部分的人,在部分程度上,解决部分的问题。
未必所有人都需要自律;
未必所有需要自律的人都适合本文提出的方法;
未必所有适合的人都能理解它;
更未必所有理解它的人都能真正从中受益。
但我自己却真切地体会过,在过去的十几年里,因为缺乏自律而经历的悔恨、错过的机会、产生的内耗与无力感。
人海茫茫中,会不会还有第二个我呢?如果真的有这样一个人,我愿意为他/她撑起一把小伞。
哪怕这把伞在世上每一千个人中,只能帮助到一个与曾经的我相似的人,那这一切,也就足够值得了。
23
说完个人,再说说社会。
时至今日,社会对抑郁症其实已经有了一定程度的理解和包容。但相比之下,对“自制力缺乏”、“拖延症”、“ADHD”等问题的理解与包容,仍远远不够。
如今,对于抑郁症患者,越来越多开明的人开始意识到,这是一种真实存在的心理疾病,而非简单的“矫情”或“想不开”。他们开始试着理解患者面临的注意力崩溃、兴趣丧失、睡眠障碍、情绪迟钝,乃至躯体化带来的真实痛苦。
然而,对于ADHD患者和长期自制力缺失者,人们的态度却往往仍然粗暴、刻薄,缺乏同理心:
- 他们的拖延、懒散、行动困难,往往被讽刺为“懒人找借口”;
- 他们陷入注意力涣散、容易成瘾的行为模式,却被看作“自控力差”“管不住自己”;
- 甚至许多用各种手段挣扎上进的ADHD患者,在为自己的失控悔恨之余,得到的却往往是“自我感动”、“心浮气躁”、“不过是假装努力而已”、“适合进厂”的冷血嘲讽。
在这样的文化氛围中,人们拒绝尊重“人类自制力存在局限”这一客观事实。很多人不愿意承认,人的主观能动性并不是无限的,它受限于神经结构、激素水平、心理状态、外界环境、长期习惯等诸多客观因素。
”自制力缺失”也从来不是靠激励,说服就可以解决的观念问题,而是一个客观存在的工程问题,系统问题,甚至医学问题。
试图用喊口号、讲鸡汤、鞭策激励、”告诉你自己如何如何“的方式去解决这类问题,就像用“你太脆弱了”、“多乐观一点”、“你看开一点不就完了吗”,来劝慰一个抑郁症患者一样可笑。
我很喜欢《了不起的盖茨比》里的那句话:
“每当你想批评别人的时候,要记住,这世上并不是所有人,都有你所拥有的那些优越条件。
正如人类的悲欢并不相通一样,在自律这件事上,人类的各方面条件也不相通。
- 有些人从小培养了良好的习惯基础,在充满上进氛围的环境中,他们或许只需要列一个计划表,每天对着镜子微笑几下,就能轻松实现Easy难度的自律;
- 而有些人却从小沉迷于手机,习惯懒散,家庭环境颓废,在这种基础上,实现自律可能是Hard难度的天堑。
自控这件事,作为我们从小普遍面对的问题,又几乎被每个人都或多或少地思考过。那么,如果上述这些人都曾思考过“如何自控”这个问题,结果会是什么呢?
这便形成了社会上对“自律”的普遍认知——或五十步而后止,或百步而后止。
自控方法的本质,不过是对自制力缺口的代偿。就像拐杖和轮椅,是残疾人运动能力的代偿一样。健康人是不需要拐杖轮椅的,伤势痊愈的患者,也不会再需要拐杖和轮椅。
一旦这个缺口被填上后,人们就不再去追求更先进的拐杖轮椅。于是,答案就变成了“小马过河”:Easy难度的人会说对着镜子微笑就行;Medium难度的人会建议你放下手机、制定计划;Hard难度的人则认为必须要靠外界监督,甚至开直播学习才行。
而一个极其反直觉的社会现象,正是来源于此。
在个人成就中,自律其实只是众多因素之一。那些Easy难度的玩家,除了更容易实现自律外,本身还拥有更好的习惯基础、环境帮助和社会资源,从而也更容易获取成就。因此,假如去观察那些取得成就的人,你会发现他们大概率正是从“Easy难度”中走来。在他们眼中,自律本就像在电梯里做俯卧撑一样轻而易举。
这样便形成了一个诡异的幸存者偏差——越是取得成就的人,反而越可能使用低效的自律手段。正如越健康的人,越缺乏使用拐杖和轮椅的真实经验一样。
更可怕的是,当社会将这些Easy模式玩家树立为所有人的榜样,赋予他们至高无上的话语权时,就形成了对真正自制力缺失者极为残忍的、“何不食肉糜”的氛围。
我不知道自己刷到过多少所谓“过来人”的评论,他们对自控方法这件事嗤之以鼻,在他们口中,“我们当年就是华山一条道,干就完了,努力就完了,哪来那么多弯弯绕绕?”
还有一次,刷到过一个高考状元的访谈视频。当主持人问及“如何看待许多学生颓废、抑郁,没有动力、无法自律”的问题时,那位高考状元稍稍顿了一下,扬起骄傲而稚嫩的脸庞,诚恳而疑惑地表示:
“说实话,我是不太能理解为什么有人居然会没有动力的。”
也许在他的世界里,自律就如同呼吸和走路一样简单,动力就像每天的太阳一样理所当然。于是,他或许并非带着恶意,只是单纯地,无法理解。
更多的时候,我们还能看到许多顶着光鲜亮丽title的营销号和自媒体博主分享的所谓“自律经验”。点进去一看,全篇说的居然是“因为爱”“因为高能量”,这尚且算是正常的,更多的博主,则是在开班授课,张口“思维模型”,闭口“认知升级”,又是道,又是禅,又是能量升华,又是心灵疗愈的。
我并非批评那些顺风顺水的人,这并不是他们的错。
我只是试图指出一个事实——人类的经历,并不天然相通;人的主观努力,也从来不能脱离客观条件单独存在。
当然,我们不能指望所有人都理解复杂的心理机制、行为科学,我们甚至不能指望每个人都足够善良。
但是,我愿意在那些走了五十步、一百步的人之外,作为一个自制力基础极差的ADHD患者,从最低的起点,去踏上那上千步的长征。以至于这两代方法背后,是数百个失败的idea,当前互联网上和相关书籍中出现过的成百上千种方法论,每个我都想过,试过,分析过。这之后,我才算是抵达了终点——终于拥有了一个正常人的自律水平。
或许吧,或许这条路只适合我一个人。但是亲爱的陌生人,若它能帮到哪怕一个人,哪怕只是你,那么我也觉得这一切足够值得。
我希望它,能在当下琳琅满目的“放下手机”“制定计划”想象未来“”告诉自己“的排列组合式的,模糊的“advice”之外,走出一条截然不同的,属于“technology”的新路。
“成吉思汗的骑兵,攻击速度与20世纪的装甲部队相当;北宋的床弩,射程达一千五百米,与20世纪的狙击步枪差不多;但这些仍不过是古代的骑兵与弓弩而已,不可能与现代力量抗衡。基础理论决定一切,未来史学派清楚地看到了这一点。”
这,才是我写下这篇文章最真实的原因。
24
最后再说一下,这篇内容绝不用于任何盈利,不建立任何社群,也不需要关注和赞赏。金钱可以赚来也可以花去,关注可以汇聚也可以消散,但是思想和技术永远在那里。
倘若这篇文章能有幸使人从中受益,我唯一的愿望,并不是你的点赞和回报,而是希望更多人对条件,习惯,成就,学历不如自己的人能多一分尊重和同理心,我也就心满意足了。
最后,请让我效仿一个MIT License作为结尾:
任何人都有权利免费且无限制地使用、复制、修改、合并、出版、传播、再授权和/或销售本文中的内容副本,并允许将这些内容用于商业目的,而不必向作者征得许可或支付任何费用,只需注明原作者即可。 所有将本文改编成视频,漫画,推文等产生的所有收益归改编者所有,本文作者分文不取。
这篇文章的目的,正是我在这篇回答的结尾中提到的——全世界的无产者,联合起来!